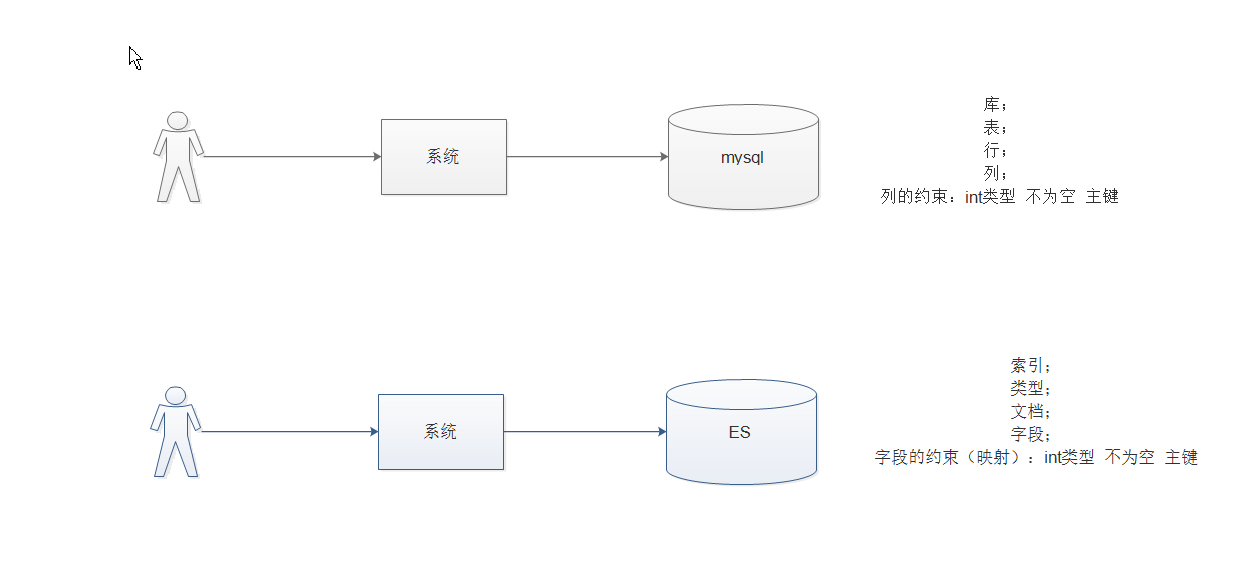
Appearance
ElasticSearch
1 ElasticSearch简介
1.1 什么是ElasticSearch?
ElasticSearch是一个基于Lucene的搜索服务器。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便。
我们建立一个网站或应用程序,并要添加搜索功能,但是想要完成搜索工作的创建是非常困难的。我们希望搜索解决方案要运行速度快,我们希望能有一个零配置和一个完全免费的搜索模式,我们希望能够简单地使用JSON通过HTTP来索引数据,我们希望我们的搜索服务器始终可用,我们希望能够从一台开始并扩展到数百台,我们要实时搜索,我们要简单的多租户,我们希望建立一个云的解决方案。因此我们利用Elasticsearch来解决所有这些问题及可能出现的更多其它问题。
ElasticSearch,简称为es, es是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理PB级别的数据。es也使用Java开发并使用Lucene作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的RESTful API来隐藏Lucene的复杂性,从而让全文搜索变得简单。
elasticsearch相当于数据库。
1.2 ElasticSearch的使用案例
Github:2013年初,GitHub抛弃了Solr,采取ElasticSearch 来做PB级的搜索。 “GitHub使用ElasticSearch搜索20TB的数据,包括13亿文件和1300亿行代码”
维基百科:启动以elasticsearch为基础的核心搜索架构
SoundCloud:“SoundCloud使用ElasticSearch为1.8亿用户提供即时而精准的音乐搜索服务”
百度:百度目前广泛使用ElasticSearch作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部20多个业务线(包括casio、云析分、网盟、预测、文库、直达号、钱包、风控等),单集群最大100台机器,200个ES节点,每天导入30TB+数据
新浪:使用ES 分析处理32亿条实时日志
阿里:使用ES 构建挖财自己的日志采集和分析体系
1.3 ElasticSearch对比Solr
| 比较点 | Solr | ElasticSearch |
|---|---|---|
| 管理模式 | 利用 Zookeeper 进行分布式管理 | 自身带有分布式协调管理功能 |
| 数据格式 | 支持多格式的数据 | 仅支持json文件格式 |
| 功能提供 | 官方提供的功能更多 | 注重于核心功能,高级功能多由第三方插件提供 |
| 应用场景 | 传统的搜索应用 | 实时搜索应用 |
| RestFul风格编程 | 不支持 | 支持 |
1.4 理解倒排索引
通常我们搜索某些东西,是通过内容,找词 这样容易区分,这种方式成为正向搜索,那么数据量大就效率低,那么还有一种就是倒排索引方式, 可以通过词去找内容,这样速度就非常快了。如下图所示:
文章数据如下:
json
一篇文章1
{
id:1
name:"杨慎",
title:"临江仙·滚滚长江东逝水",
content:"滚滚长江东逝水,浪花淘尽英雄"
}
一篇文章2
{
id:2
name:"苏轼",
title:"念奴娇·赤壁怀古",
content:"大江东去,浪淘尽,千古风流人物"
}
一篇文章3
{
id:3
name:"柳宗元",
title:"江雪",
content:"孤舟蓑笠翁,独钓寒江雪"
}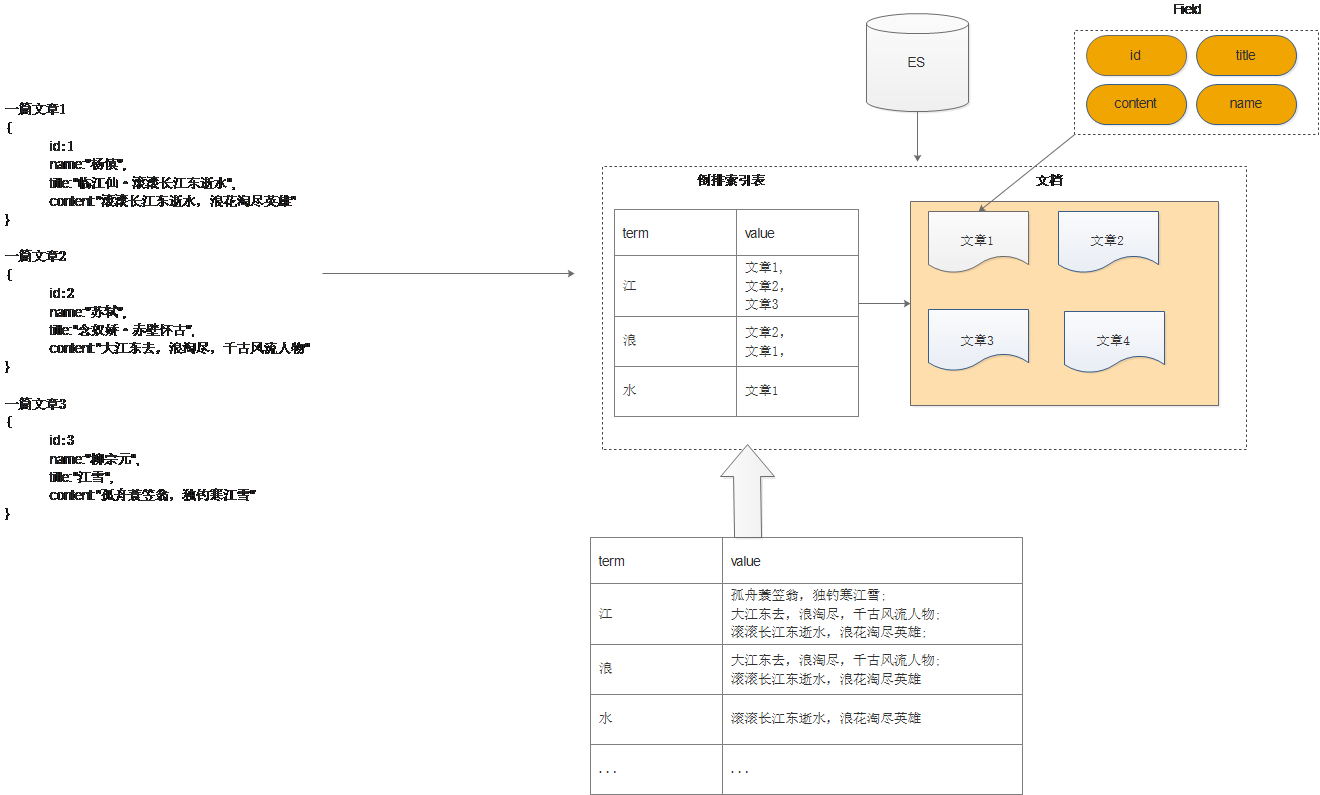
要建立倒排索引表,需要
先对文本进行分词(理解成按照一定规则拆分出词条和值),也就是将词语进行切分然后形成如上的结构和映射关系。比如下边
json
临 ---->文章数据
title:江 ---->文章1 解释(title:中分出来江这个词 对应 的有文章1)
content:江 ----->文章1,文章2 解释(content:种分出来讲这个词 对应 有文章1和文章2)
仙
滚
滚
长
江
东
逝
水那么这个过程就是分词,分词的过程需要有分词器来进行。我们有许多的分词器,默认就是标准分词器。
什么是倒排索引? 见其名知其意,有倒排索引,对应肯定,有正向索引。
正向索引(forward index),反向索引(inverted index)更熟悉的名字是倒排索引。
在搜索引擎中每个文件都对应一个文件ID,文件内容被表示为一系列关键词的集合(实际上在搜索引擎索引库中,关键词也已经转换为关键词ID)。例如“文档1”经过分词,提取了20个关键词,每个关键词都会记录它在文档中的出现次数和出现位置。
正向索引的结构如下:
“文档1”的ID > 单词1:出现次数,出现位置列表;单词2:出现次数,出现位置列表;…………。
“文档2”的ID > 此文档出现的关键词列表。
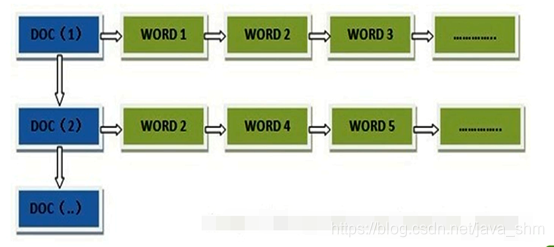
一般是通过key,去找value。
当用户在主页上搜索关键词“华为手机”时,假设只存在正向索引(forward index),那么就需要扫描索引库中的所有文档,找出所有包含关键词“华为手机”的文档,再根据打分模型进行打分,排出名次后呈现给用户。因为互联网上收录在搜索引擎中的文档的数目是个天文数字,这样的索引结构根本无法满足实时返回排名结果的要求。
所以,搜索引擎会将正向索引重新构建为倒排索引,即把文件ID对应到关键词的映射转换为关键词到文件ID的映射,每个关键词都对应着一系列的文件,这些文件中都出现这个关键词。
倒排索引的结构如下:
“关键词1”:“文档1”的ID,“文档2”的ID,…………。 “关键词2”:带有此关键词的文档ID列表。
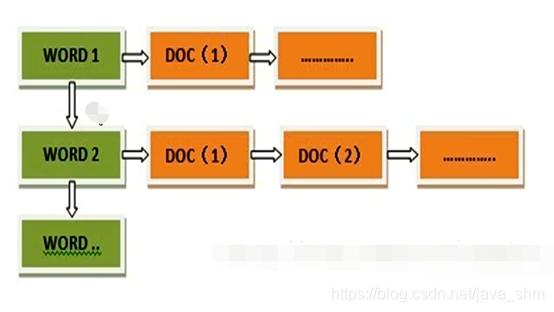
从词的关键字,去找文档。
2 ElasticSearch安装与启动
2.1下载ES压缩包
ElasticSearch分为Linux和Window版本,基于我们主要学习的是ElasticSearch的Java客户端的使用。
ElasticSearch的官方地址: https://www.elastic.co/products/elasticsearch

2.2 安装ES服务
Window版的ElasticSearch的安装很简单,类似Window版的Tomcat,解压开即安装完毕,解压后的ElasticSearch的目录结构如下:
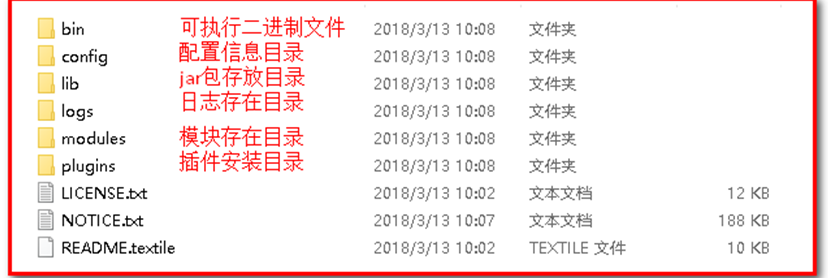
注意:ES的目录不要出现中文,也不要有特殊字符。
2.3 启动ES服务
启动:
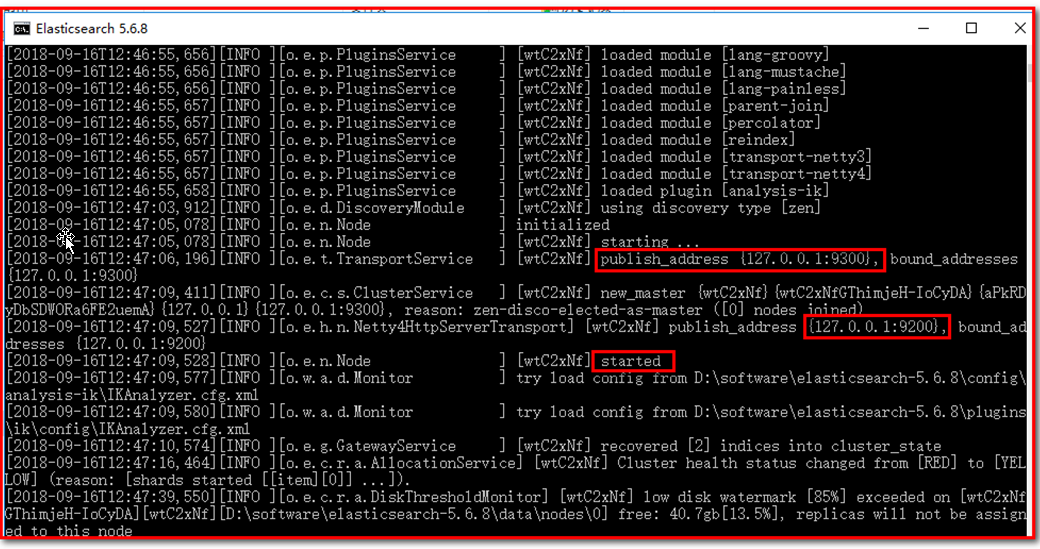
注意:
9300是tcp通讯端口,集群间和TCPClient都执行该端口,可供java程序调用;
9200是http协议的RESTful接口 。
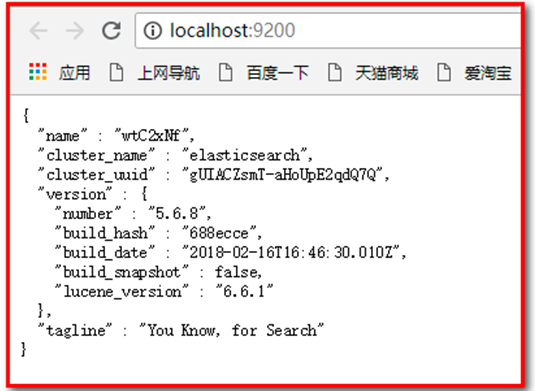
通过浏览器访问ElasticSearch服务器,看到如下返回的json信息,代表服务启动成功:
注意事项:
(1)ElasticSearch5是使用java开发的,且本版本的es需要的jdk版本要是1.8以上,所以安装ElasticSearch之前保证JDK1.8+安装完毕,并正确的配置好JDK环境变量,否则启动ElasticSearch失败
(2)出现闪退,通过路径访问发现“空间不足”
修改:解压目录下的/config/jvm.options文件

2.4 安装ES的图形化界面插件
ElasticSearch不同于Solr自带图形化界面,我们可以通过安装ElasticSearch的head插件,完成图形化界面的效果,完成索引数据的查看。
*elasticsearch-5-以上版本安装head插件,需要先安装 nodejs 以及 grunt
2.4.1 安装nodejs

下载nodejs:https://nodejs.org/en/download/
双击如图所示msi文件,下一步即可。安装成功后,执行cmd命令查看版本:
shell
node -v
2.4.2 安装ES head 插件
1)下载如下图已经下载完毕
2)解压rar
copy rar文件到另外一个不带中文和空格的目录,并解压
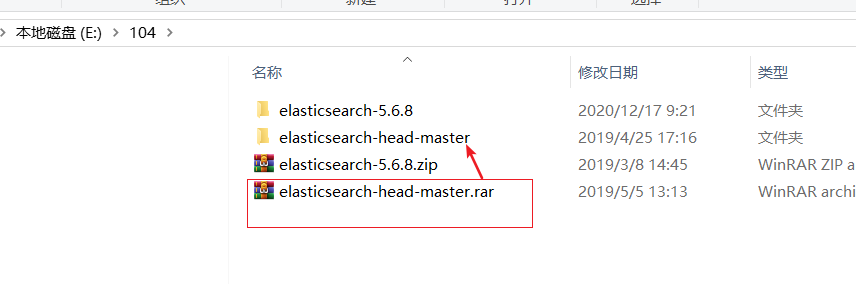
3)cd到目录elasticsearch-head-master中 执行命令
shell
npm run start2.4.3 配置ES支持head插件
修改elasticsearch/config下的配置文件:elasticsearch.yml,增加以下配置:
yaml
http.cors.enabled: true
http.cors.allow-origin: "*"
network.host: 127.0.0.1注意有空格:
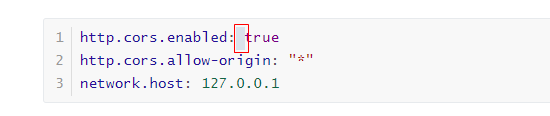
解释:
yaml
http.cors.enabled: true:此步为允许elasticsearch跨域访问,默认是false。
http.cors.allow-origin: "*":表示跨域访问允许的域名地址(*表示任意)。
network.host:127.0.0.1:主机域名2.4.4 访问head插件
1) 重启ES服务器
2)进入head插件的目录 执行cmd命令(如果已经启动则不用再执行):
shell
npm run start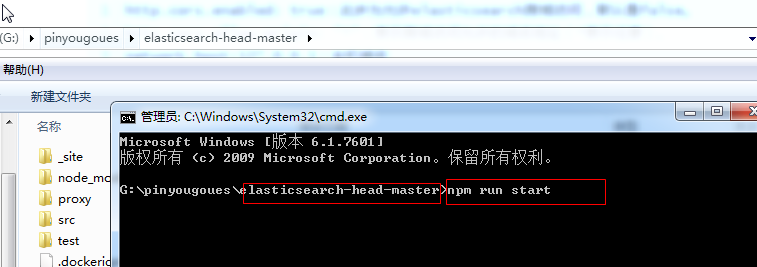
3 ElasticSearch相关概念
3.1 概述
Elasticsearch是面向文档(document oriented)的,这意味着它可以存储整个对象或文档(document)。然而它不仅仅是存储(store),还会索引(index)每个文档的内容使之可以被搜索。在Elasticsearch中,你可以对文档(而非成行成列的数据)进行索引、搜索、排序、过滤。Elasticsearch比较传统关系型数据库如下:
json
Relational DB -> Databases -> Tables -> Rows -> Columns
Elasticsearch -> Indices -> Types -> Documents -> Fields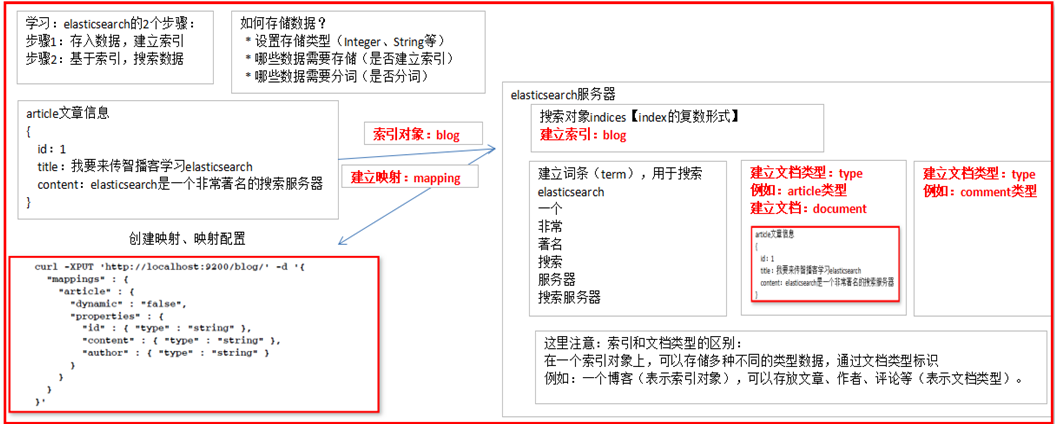
3.2 核心概念
3.2.1 索引 index
一个索引就是一个拥有几分相似特征的文档的集合。比如说,你可以有一个客户数据的索引,另一个产品目录的索引,还有一个订单数据的索引。一个索引由一个名字来标识(必须全部是小写字母的),并且当我们要对对应于这个索引中的文档进行索引、搜索、更新和删除的时候,都要使用到这个名字。在一个集群中,可以定义任意多的索引。
3.2.2. 类型 type
在一个索引中,你可以定义一种或多种类型。一个类型是你的索引的一个逻辑上的分类/分区,其语义完全由你来定。通常,会为具有一组共同字段的文档定义一个类型。比如说,我们假设你运营一个博客平台并且将你所有的数据存储到一个索引中。在这个索引中,你可以为用户数据定义一个类型,为博客数据定义另一个类型,当然,也可以为评论数据定义另一个类型。
3.2.3. 文档 document
一个文档是一个可被索引的基础信息单元。比如,你可以拥有某一个客户的文档,某一个产品的一个文档,当然,也可以拥有某个订单的一个文档。文档以JSON(Javascript Object Notation)格式来表示,而JSON是一个到处存在的互联网数据交互格式。
在一个index/type里面,你可以存储任意多的文档。注意,尽管一个文档,物理上存在于一个索引之中,文档必须被索引/赋予一个索引的type。
注意:每一篇文档注意在进行创建的时候都会进行打分。用于进行排名,打分的公式实际上用的就是lucece的打分公式。
3.2.4. 字段Field
相当于是数据表的字段,对文档数据根据不同属性进行的分类标识
3.2.5. 映射 mapping
mapping是处理数据的方式和规则方面做一些限制,如某个字段的数据类型、默认值、分词器、是否被索引等等,这些都是映射里面可以设置的,其它就是处理es里面数据的一些使用规则设置也叫做映射,按着最优规则处理数据对性能提高很大,因此才需要建立映射,并且需要思考如何建立映射才能对性能更好。
例如:

Field中有四个重要的属性:数据类型,是否分词 是否存储 是否索引. 类似于指定数据库中的表中的列的一些约束,需要根据不同的应用场景来决定使用哪种数据类型和属性值。
- 数据类型 定义了该Field的数据存储的方式 有基本数据类型 和 字符串类型以及 复杂的数据类型
- 是否分词 定义了该字段的值是否要被索引。分词的目的就是为了要索引
- 是否索引 定义了该字段是否要被搜索 要索引的目的就是为了要搜索
- 是否存储 定义了是否该存储该数据到底层的lucene中.默认是不存储的。存储不存储看页面是否需要展示
3.2.6. 接近实时 NRT
Elasticsearch是一个接近实时的搜索平台。这意味着,从索引一个文档直到这个文档能够被搜索到有一个轻微的延迟(通常是1秒以内)
3.2.7. 集群 cluster
一个集群就是由一个或多个节点组织在一起,它们共同持有整个的数据,并一起提供索引和搜索功能。一个集群由一个唯一的名字标识,这个名字默认就是“elasticsearch”。这个名字是重要的,因为一个节点只能通过指定某个集群的名字,来加入这个集群。
3.2.8. 节点 node
一个节点是集群中的一个服务器,作为集群的一部分,它存储数据,参与集群的索引和搜索功能。和集群类似,一个节点也是由一个名字来标识的,默认情况下,这个名字是一个随机的角色的名字,这个名字会在启动的时候赋予节点。这个名字对于管理工作来说挺重要的,因为在这个管理过程中,你会去确定网络中的哪些服务器对应于Elasticsearch集群中的哪些节点。
一个节点可以通过配置集群名称的方式来加入一个指定的集群。默认情况下,每个节点都会被安排加入到一个叫做“elasticsearch”的集群中,这意味着,如果你在你的网络中启动了若干个节点,并假定它们能够相互发现彼此,它们将会自动地形成并加入到一个叫做“elasticsearch”的集群中。
在一个集群里,只要你想,可以拥有任意多个节点。而且,如果当前你的网络中没有运行任何Elasticsearch节点,这时启动一个节点,会默认创建并加入一个叫做“elasticsearch”的集群。
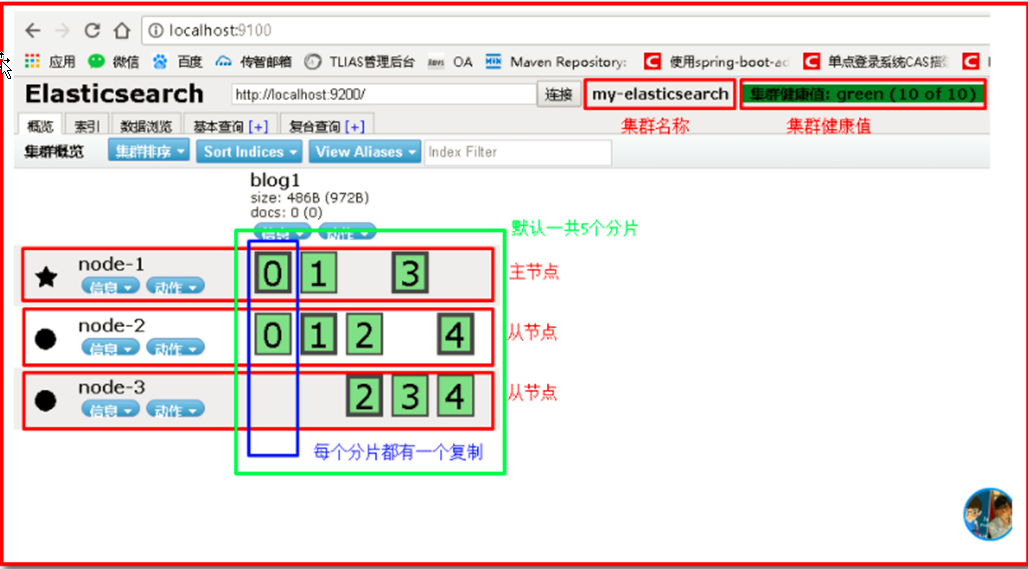
3.2.9. 分片 和 复制 shards & replicas
一个索引可以存储超出单个节点硬件限制的大量数据。比如,一个具有10亿文档的索引占据1TB的磁盘空间,而任一节点都没有这样大的磁盘空间;或者单个节点处理搜索请求,响应太慢。为了解决这个问题,Elasticsearch提供了将索引划分成多份的能力,这些份就叫做分片。当你创建一个索引的时候,你可以指定你想要的分片的数量。每个分片本身也是一个功能完善并且独立的“索引”,这个“索引”可以被放置到集群中的任何节点上。分片很重要,主要有两方面的原因: 1)允许你水平分割/扩展你的内容容量。 2)允许你在分片(潜在地,位于多个节点上)之上进行分布式的、并行的操作,进而提高性能/吞吐量。
至于一个分片怎样分布,它的文档怎样聚合回搜索请求,是完全由Elasticsearch管理的,对于作为用户的你来说,这些都是透明的。
在一个网络/云的环境里,失败随时都可能发生,在某个分片/节点不知怎么的就处于离线状态,或者由于任何原因消失了,这种情况下,有一个故障转移机制是非常有用并且是强烈推荐的。为此目的,Elasticsearch允许你创建分片的一份或多份拷贝,这些拷贝叫做复制分片,或者直接叫复制。
复制之所以重要,有两个主要原因: 在分片/节点失败的情况下,提供了高可用性。因为这个原因,注意到复制分片从不与原/主要(original/primary)分片置于同一节点上是非常重要的。扩展你的搜索量/吞吐量,因为搜索可以在所有的复制上并行运行。总之,每个索引可以被分成多个分片。一个索引也可以被复制0次(意思是没有复制)或多次。一旦复制了,每个索引就有了主分片(作为复制源的原来的分片)和复制分片(主分片的拷贝)之别。分片和复制的数量可以在索引创建的时候指定。在索引创建之后,你可以在任何时候动态地改变复制的数量,但是你事后不能改变分片的数量。
默认情况下,Elasticsearch中的每个索引被分片5个主分片和1个复制,这意味着,如果你的集群中至少有两个节点,你的索引将会有5个主分片和另外5个复制分片(1个完全拷贝),这样的话每个索引总共就有10个分片。
4. 操作ElasticSearch
操作ES就相当于对操作数据库,我们应该知道针对数据库我们有不同的CRUD功能,那么同样的道理,操作elasticsearch也能有CRUD功能,只不过叫法不一样。有两种方式:如下:
- 使用Elasticsearch提供的restfull风格的API操作ES
- 使用elasticsearch提供的java Client API来操作ES 又有许多方式,我们这里主要使用springboot集成spring data elasticsearch来实现
- java API 使用官方提供的TransportClient
- java API 使用 REST clients
- java api 使用 Jest
- java api 使用 spring data elasticsearch
4.1 搭建ElasticSearch操作环境
4.1.1 创建springboot工程
创建一个springboot工程,注意添加springboot 的spring data elasticsearch的起步依赖,我们使用该起步依赖中的transport-elasticsearch的官方的API
4.1.2 pom.xml
xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.1.4.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-web</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
</project>4.1.3 配置连接服务器地址
创建yml文件:
yaml
server:
port: 8080
spring:
data:
elasticsearch:
cluster-nodes: 127.0.0.1:9300
cluster-name: elasticsearch4.2 操作ElasticSearch
4.2.1 新建索引+添加文档
使用创建索引+自动创建映射
(1)创建POJO 用于存储数据转成JSON
java
public class Article implements Serializable {
private Long id;
private String content;
private String title;
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
}(2)创建测试类并完成创建索引和添加文档(自动添加映射)创建测试类
java
@SpringBootTest
@RunWith(SpringRunner.class)
public class EsApplicationTest01 {
@Autowired
private TransportClient transportClient;
@Autowired
private ObjectMapper objectMapper;
//创建索引 并 添加文档 增加 //修改文档
@Test
public void createIndexAndDocument() throws Exception {
//设置数据
Article article = new Article();
article.setTitle("华为手机很棒");
article.setContent("华为手机真的很棒");
article.setId(1L);
IndexResponse indexResponse = transportClient
.prepareIndex("blog01", "article", "1")
.setSource(objectMapper.writeValueAsString(article), XContentType.JSON)
.get();
System.out.println(indexResponse);
}
}4.2.2 根据ID查询文档
java
//根据Id获取数据
@Test
public void getById() {
GetResponse documentFields = transportClient.prepareGet("blog01", "article", "1").get();
System.out.println(documentFields.getSourceAsString());
}4.2.3 根据ID删除文档
java
//删除文档
@Test
public void deleteById() {
transportClient.prepareDelete("blog01", "article", "1");
}5 分词器和ElasticSearch集成使用
5.1 分词器
说明倒排索引的时候说过,在进行数据存储的时候,需要先进行分词。而分词指的就是按照一定的规则将词一个个切割。这个规则是有内部的分词器机制来决定的,不同的分词器就是不同的规则
- standard分词器
- ik分词器
- stop分词器
- 其他的分词器
分词的过程比较复杂,不同的分词器就有不同的规则,例如:
text
如有一段文本:Lucene is a full-text search java
使用标准分词器:
浏览器地址输入:http://localhost:9200/_analyze?analyzer=standard&text=Lucene is a full-text search java
最终形成词汇为:
Lucene
is
a
full
text
search
java
使用停用分词器:
浏览器地址输入:http://localhost:9200/_analyze?analyzer=stop&text=Lucene is a full-text search java
最终形成词汇为:
lucene
full
text
search
java5.2 IK分词器
5.2.1 什么是IK分词器
以上针对英文可以,但是如果使用中文的话,分词效果不好,
IK分词是一款国人开发的相对简单的中文分词器。虽然开发者自2012年之后就不在维护了,但在工程应用中IK算是比较流行的一款!
特点: 1. 能将原本不是词的变成一个词 2. 分词效果优秀 3. 能将原本是一个词的进行停用,这些词我们称为停用词。停用词:单独运用没有具体语言意义的词汇,可根据语义自己定义。
5.2.2 IK分词器安装
下载地址:
https://github.com/medcl/elasticsearch-analysis-ik/releases- 先将其解压,将解压后的elasticsearch文件夹重命名文件夹为ik
- 将ik文件夹拷贝到elasticsearch/plugins 目录下。
- 重新启动,即可加载IK分词器
5.2.3 IK分词器测试
IK提供了两个分词算法ik_smart 和 ik_max_word. 其中 ik_smart 为最少切分(智能切分),ik_max_word为最细粒度划分
- 第一种:最小切分
- 第二种:种最细切分
测试第一种:浏览器中输入:
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是程序员
测试第二种:浏览器输入:
http://127.0.0.1:9200/_analyze?analyzer=ik_max_word&pretty=true&text=我是程序员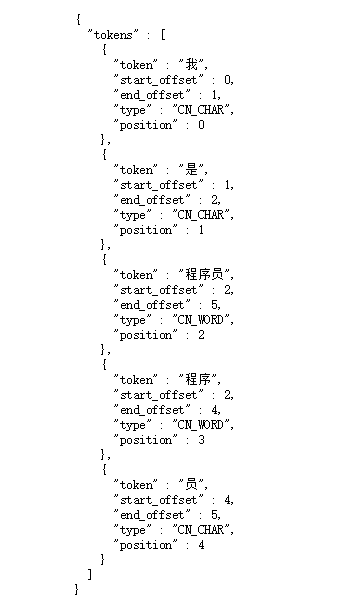
5.2.4 自定义词库/词典
5.2.4.1 测试分词效果
(1)我们现在测试"明港建设",
浏览器的测试效果如下 http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=明港建设
json
{
"tokens" : [
{
"token" : "明",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "港",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "建",
"start_offset" : 2,
"end_offset" : 3,
"type" : "CN_CHAR",
"position" : 2
},
{
"token" : "设",
"start_offset" : 3,
"end_offset" : 4,
"type" : "CN_CHAR",
"position" : 3
}
]
}(2)再测试:
java
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=lucene is a full-text java 中国啊伟大的祖国json
{
"tokens": [
{
"token": "lucene",
"start_offset": 0,
"end_offset": 6,
"type": "ENGLISH",
"position": 0
},
{
"token": "a",
"start_offset": 10,
"end_offset": 11,
"type": "ENGLISH",
"position": 1
},
{
"token": "full-text",
"start_offset": 12,
"end_offset": 21,
"type": "LETTER",
"position": 2
},
{
"token": "java",
"start_offset": 22,
"end_offset": 26,
"type": "ENGLISH",
"position": 3
},
{
"token": "中国",
"start_offset": 27,
"end_offset": 29,
"type": "CN_WORD",
"position": 4
},
{
"token": "啊",
"start_offset": 29,
"end_offset": 30,
"type": "CN_CHAR",
"position": 5
},
{
"token": "伟大",
"start_offset": 30,
"end_offset": 32,
"type": "CN_WORD",
"position": 6
},
{
"token": "祖国",
"start_offset": 33,
"end_offset": 35,
"type": "CN_WORD",
"position": 7
}
]
}5.2.4.2 添加自定义词库/词典
(1)通过测试1发现,明港建设没有作为整体被分词出来。我们需要将其扩展为一个词,此时我们需要自定义扩展词典
- 进入elasticsearch/plugins/ik/config目录
- 新建一个my.dic文件(文件名任意),特别注意编辑内容(以utf8无bom保存, 如果不行加一些换行)
text
明港建设- 修改IKAnalyzer.cfg.xml(在ik/config目录下)
xml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!‐‐用户可以在这里配置自己的扩展字典 ‐‐>
<entry key="ext_dict">my.dic</entry>
<!‐‐用户可以在这里配置自己的扩展停止词字典‐‐>
<entry key="ext_stopwords"></entry>
</properties>(2)测试二我们发现有些词我们需要分出来,比如 “啊”
- 如果需要停用一些词,比如有些文本在进行创建文档建立倒排索引的时候需要过滤掉一些没有用的词,则可以进行自定义词典:我们把他叫做停用词典
(1)进入elasticsearch/plugins/ik/config目录
(2)创建一个stopwords.dic 文件,特别注意:编辑内容(以utf8无bom保存, 如果不行加一些换行)
(3)在文件中添加一个字为:的
(4)修改IKAnalyzer.cfg.xml(在ik/config目录下)
yaml
<properties>
<comment>IK Analyzer 扩展配置</comment>
<!‐‐用户可以在这里配置自己的扩展字典 ‐‐>
<entry key="ext_dict">my.dic</entry>
<!‐‐用户可以在这里配置自己的扩展停止词字典‐‐>
<entry key="ext_stopwords">stopwords.dic</entry>
</properties>(5)重启eslasticesarch服务器查看效果浏览器中输入:
json
http://127.0.0.1:9200/_analyze?analyzer=ik_smart&pretty=true&text=我是明港建设的职工查看分词效果:并没有出现的,说明这个词已经被过滤掉了。
json
{
"tokens": [
{
"token": "我",
"start_offset": 0,
"end_offset": 1,
"type": "CN_CHAR",
"position": 0
},
{
"token": "是",
"start_offset": 1,
"end_offset": 2,
"type": "CN_CHAR",
"position": 1
},
{
"token": "明港建设",
"start_offset": 2,
"end_offset": 6,
"type": "CN_WORD",
"position": 2
},
{
"token": "职工",
"start_offset": 7,
"end_offset": 9,
"type": "CN_WORD",
"position": 3
}
]
}6.ElasticSearch常用编程操作 (6.X版本)
6.1索引相关操作
java
@SpringBootTest
@RunWith(SpringRunner.class)
public class EsApplicationTest03 {
@Autowired
private TransportClient transportClient;
@Autowired
private ObjectMapper objectMapper;
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
//@Autowired
//private ArticleDao dao;
}1.1创建索引
java
@Test
public void createIndex() {
//准备创建索引 ,指定索引名 执行创建的动作(get方法)
transportClient.admin().indices().prepareCreate("blog03").get();
}1.2删除索引
java
//删除索引
@Test
public void deleteIndex() {
//准备删除索引 ,指定索引名 指定删除的动作(get)
transportClient.admin().indices().prepareDelete("blog02").get();
}6.2映射相关操作
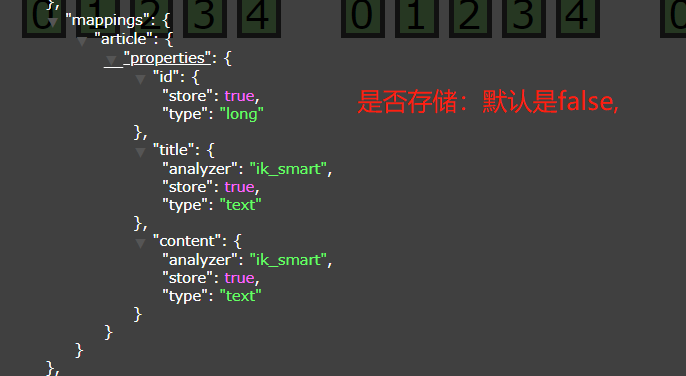
6.2.1映射格式
json
"mappings" : {
"article" : {
"properties" : {
"id" : { "type" : "long","store":"true" },
"title" : { "type" : "text","analyzer":"ik_smart","index":"true","store":"true" },
"content" : { "type" : "text","analyzer":"ik_smart","index":"true","store":"true" }
}
}
}6.2.2创建映射
java
@Test
public void putMapping() throws Exception {
//1.创建索引
transportClient.admin().indices().prepareCreate("blog02").get();
//2.创建映射
XContentBuilder builder = XContentFactory.jsonBuilder()
.startObject()
.startObject("article")
.startObject("properties")
.startObject("id")
.field("type", "long").field("store", "true")
.endObject()
.startObject("title")
.field("type", "text").field("analyzer", "ik_smart").field("store", "true")
.endObject()
.startObject("content")
.field("type", "text").field("analyzer", "ik_smart").field("store", "true")
.endObject()
.endObject()
.endObject()
.endObject();
PutMappingRequest mapping = new PutMappingRequest("blog02").type("article").source(builder);
transportClient.admin().indices().putMapping(mapping).get();
}
6.3文档相关操作
6.3.1创建文档
6.3.1.1通过ObjectMapper进行创建
java
//创建文档 /更新文档 使用的是ik分词器
@Test
public void createIndexAndDocument() throws Exception {
//设置数据
Article article = new Article();
article.setTitle("华为手机很棒");
article.setContent("华为手机真的很棒");
article.setId(1L);
IndexResponse indexResponse = transportClient
.prepareIndex("blog02", "article", "1")
.setSource(objectMapper.writeValueAsString(article), XContentType.JSON)
.get();
System.out.println(indexResponse);
}6.3.1.2使用xcontentBuidler方式进行创建
- 提供JSON如下
json
{
"id": 1,
"content": "华为手机真的很棒",
"title": "华为手机很棒"
}- 实现创建文档
java
//创建使用JSON xcontentbuilder的方式来创建文档
/**
*
* {
"id": 1,
"content": "华为手机真的很棒",
"title": "华为手机很棒"
}
*
* @throws Exception
*/
@Test
public void createDocumentByJsons() throws Exception{
XContentBuilder xContentBuilder = XContentFactory.jsonBuilder()
.startObject()
.field("id",2)
.field("content","华为手机真的很棒你猜猜")
.field("title","华为手机很棒但是我现在真的忧桑")
.endObject();
IndexResponse indexResponse = transportClient.prepareIndex("blog02", "article", "2").setSource(xContentBuilder).get();
System.out.println(indexResponse);
}6.3.2修改文档
注意 修改文档和新增文档一样。当存在相同的文档的唯一ID的时候,便是更新。
6.3.3删除文档
java
//删除文档
@Test
public void deleteByDocument() {
transportClient.prepareDelete("blog02", "article", "2").get();
}6.3.4查询文档
6.3.4.1批量添加文档数据
批量添加数据,我们可能想到的是直接循环,然后每个循环里面去提交,但是这样的话,效率很低。我们采用批量添加的方式,一次性提交数据。
java
//批量添加文档
@Test
public void createDocument() throws Exception {
//构建批量添加builder
BulkRequestBuilder bulkRequestBuilder = transportClient.prepareBulk();
long start = System.currentTimeMillis();
for (long i = 0; i < 100; i++) {
//数据构建
Article article = new Article();
article.setTitle("华为手机很棒" + i);
article.setContent("华为手机真的很棒啊" + i);
article.setId(i);
//转成JSON
String valueAsString = objectMapper.writeValueAsString(article);
//设置值
IndexRequest indexRequest = new IndexRequest("blog02", "article", "" + i).source(valueAsString, XContentType.JSON);
//添加请求对象buidler中
bulkRequestBuilder.add(indexRequest);
}
//一次性提交
BulkResponse bulkItemResponses = bulkRequestBuilder.get();
long end = System.currentTimeMillis();
System.out.println("消耗了:"+(end-start)/1000);
System.out.println("获取状态:" + bulkItemResponses.status());
if (bulkItemResponses.hasFailures()) {
System.out.println("还有些--->有错误");
}
}测试结果为:
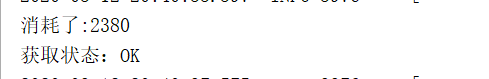
测是结果是2S秒钟就可以操作3000W条数据。
6.3.4.2文档的查询
- 查询所有数据
java
//查询所有
@Test
public void matchAllQuery() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.matchAllQuery())
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}- queryStringQuery():字符串查询
注意: 使用它是先分词再进行查询的,而且默认不指定字段时,是使用默认的分词器default_field和defaul anlzyer来进行查询,如果指定了字段,则使用之前的映射设置的分词器来进行分词,当然也可以指定分词器
java
//如果不写任何查询字段,那么会默认使用默认的分词器进行分词查询。用的是standard的标准分词器 进行查询default_field default_analyzer
// https://blog.csdn.net/u013795975/article/details/81102010
//如果指定了某一个字段,则会使用之前映射中指定的分词器进行查询。
//注意 他只能查询字符串类型数据,如果不指定字段,则会查询所有的字段的值
@Test
public void queryStringQuery() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.queryStringQuery("手机").field("title"))
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}- termQuery词条查询
java
//查询时,不分词,将其作为整体作为条件去倒排索引中匹配是否存在。 简述为:不分词,整体匹配查询
@Test
public void termQuery() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("title", "手机"))
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}- matchQuery
特点:先分词,再查询,可以指定任意数据类型。需要只当要查询的哪个字段
java
//匹配查询
//特点: 查询时,先进行分词,并分词之后再进行匹配查询将结果合并返回出来。它可以指定非字符串的查询,数字的都可以。简述为:先分词,再查询,可以指定任意数据类型
@Test
public void matchQuery() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.matchQuery("title","华为手机真的很棒啊9"))
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}- multiMatch查询
java
//多字段匹配查询
@Test
public void multiMatchQuery() {
//1.创建查询对象
//2.设置查询的条件
//3.执行查询
SearchResponse searchResponse = transportClient.prepareSearch("blog02").setTypes("article")
//匹配查询
// 参数1 指定要搜索的内容
// 参数2 指定多个字段的名称
.setQuery(QueryBuilders.multiMatchQuery("很棒", "content", "title"))
.get();
//4.获取结果
SearchHits hits = searchResponse.getHits();
System.out.println("总命中数:" + hits.getTotalHits());
for (SearchHit hit : hits) {
//5.打印
System.out.println(hit.getSourceAsString());
}
}- wildcardQuery():模糊查询
java
//模糊搜索: 也叫通配符搜索
//? 表示任意字符 一定占用一个字符空间,相当于占位符
//* 表示任意字符 可以占用也可以不占用
@Test
public void wildcardQuery() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.wildcardQuery("title", "手?"))
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
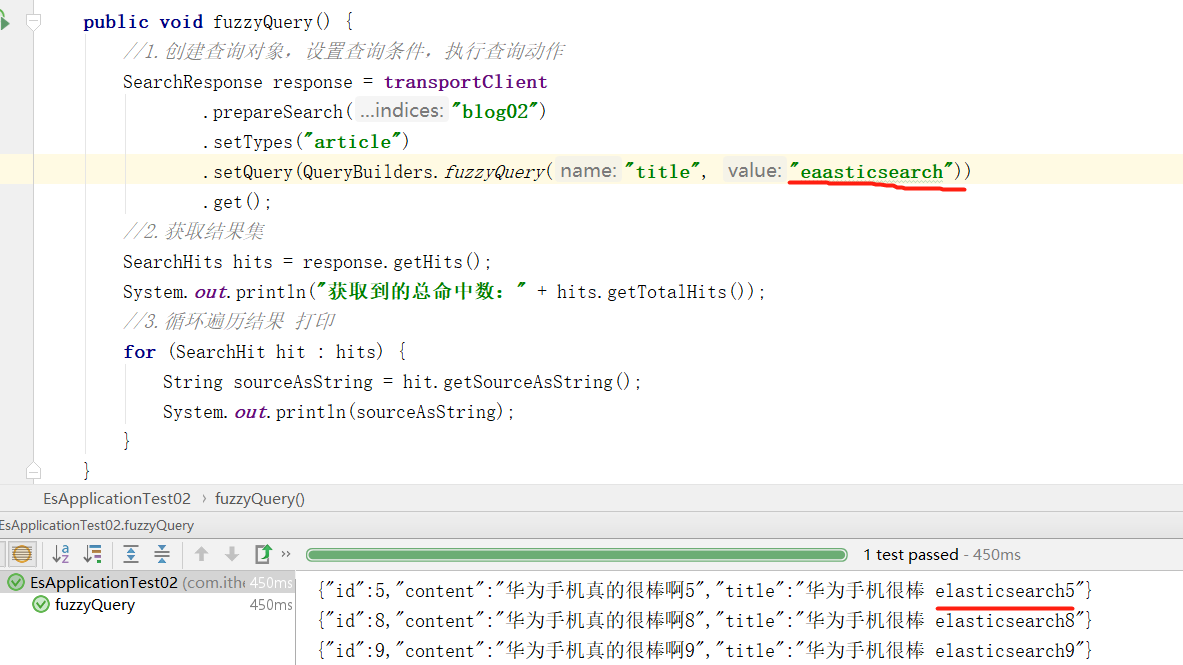
}- 相似度查询fuzzyQuery()
java
//相似度查询 输入错误的单词也能搜索出来
//
@Test
public void fuzzyQuery() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.fuzzyQuery("title", "eaasticsearch"))
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}
- 范围查询rangeQuery()
java
/**
* 范围查询:如下代码 查询id 从0 到20之间的数据包含0 和20
* from to
* gt lt
*/
@Test
public void rangeQuery() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.rangeQuery("id").from(0,true).to(20,true))
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}6.3.4.3布尔查询boolQuery
6.3.4.3.1介绍
bool查询 也叫做多条件组合查询,指在搜索过程中我们可以指定多种条件进行查询,例如:在JD我想买手机并且价格在500-2000之间的并且是苹果这个品牌的手机等等。那么这里面就需要多种条件组合在一起再执行查询。
当然执行查询的条件不一定是 都要满足,有可能是或者的关系,有可能是并且的关系,也有可能是非的关系。
Elasticsearch中定义了以下几种条件满足关系:
text
MUST 必须满足条件 相当于AND
MUST_NOT 必须不满足条件 相当于 NOT
SHOULD 应该满足条件 相当于OR
FILTER 必须满足条件 区别于MUST 它在查询上下文中查询6.3.4.3.2代码实现
需求:查询title为手机的,并且id在0-30之间的数据。
代码:
java
//多条件组合查询
//需求: 查询title为手机的,并且id在0-30之间的数据
//MUST 必须满足条件 相当于AND
//MUST_NOT 必须不满足条件 相当于 NOT
//SHOULD 应该满足条件 相当于OR
//FILTER 必须满足条件 区别于MUST 它在查询上下文中查询
@Test
public void boolquery() {
//1.创建组合条件对象
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//2.创建条件1 和条件2 将这两个条件组合在一起
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("id").from(0, true).to(30, true);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "手机");
boolQueryBuilder
.must(rangeQueryBuilder)
.must(termQueryBuilder);
//3.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(boolQueryBuilder)
.get();
//4.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//5.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}6.3.4.5过虑器
过虑是针对搜索的结果进行过虑,过虑器主要判断的是文档是否匹配,不去计算和判断文档的匹配度得分,所以过虑器性能比查询要高,且方便缓存,推荐尽量使用过虑器去实现查询或者过虑器和查询共同使用。
MUST和FILTER的区别:
text
MUST 必须满足某条件,但是需要查询和计算文档的匹配度的分数,速度要慢
FILTER 必须满足某条件,但是不需要计算匹配度分数,那么优化查询效率,方便缓存。如下使用了filter
java
@Test
public void boolquery() {
//1.创建组合条件对象
BoolQueryBuilder boolQueryBuilder = QueryBuilders.boolQuery();
//2.创建条件1 和条件2 将这两个条件组合在一起
RangeQueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("id").from(0, true).to(30, true);
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("title", "手机");
boolQueryBuilder
.filter(rangeQueryBuilder)
.filter(termQueryBuilder);
//3.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(boolQueryBuilder)
.get();
//4.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//5.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}6.3.4.6分页查询和排序
- ES支持分页查询,传入两个参数:from和size。
form:表示起始文档的下标,从0开始。 size:查询的文档数量。
- 可以在字段上添加一个或多个排序,支持在keyword、date、float等类型上添加,text类型的字段上默认是不允许添加排序。
java
//排序和分页 每页显示2行记录
//按照Id升序排列
@Test
public void pageAndSort() {
//1.创建查询对象,设置查询条件,执行查询动作
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("title", "手机"))
.setFrom(0)// (page -1)* rows
.setSize(2)//rows
.addSort("id", SortOrder.ASC)//升序
.get();
//2.获取结果集
SearchHits hits = response.getHits();
System.out.println("获取到的总命中数:" + hits.getTotalHits());
//3.循环遍历结果 打印
for (SearchHit hit : hits) {
String sourceAsString = hit.getSourceAsString();
System.out.println(sourceAsString);
}
}6.3.5查询结果高亮操作
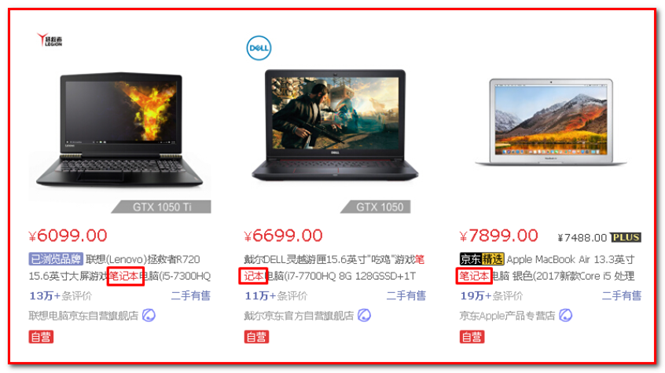
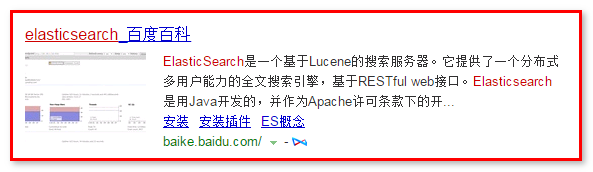
3.5.1 什么是高亮显示
在进行关键字搜索时,搜索出的内容中的关键字会显示不同的颜色,称之为高亮
- 京东商城搜索"笔记本"
- 在百度搜索"elasticsearch",查看页面源码分析
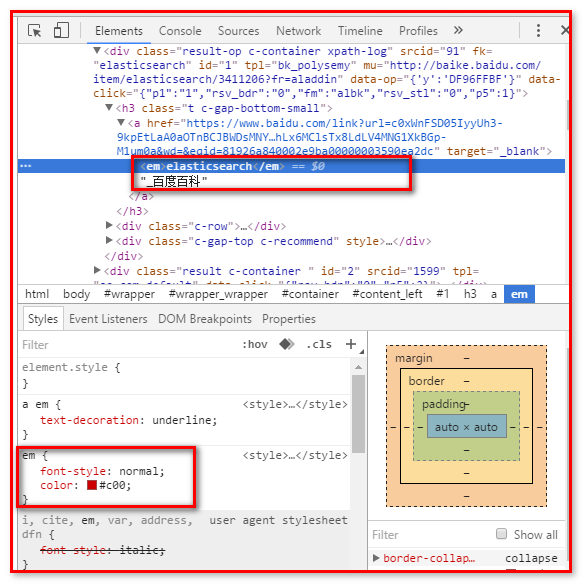
6.3.5.2高亮显示的html分析
通过开发者工具查看高亮数据的html代码实现:
ElasticSearch可以对查询出的内容中关键字部分进行标签和样式的设置,但是你需要告诉ElasticSearch使用什么标签对高亮关键字进行包裹呢?
使用<em>高亮内容</em>
6.3.5.3 高亮显示代码实现
java
@Test
public void hight() throws Exception {
//1.创建高亮配置
HighlightBuilder highlightBuilder = new HighlightBuilder();
highlightBuilder.field("title").preTags("<em style=\"color:red\">").postTags("</em>");
//2.创建查询对象,设置查询条件,设置高亮 执行查询
SearchResponse response = transportClient
.prepareSearch("blog02")
.setTypes("article")
.setQuery(QueryBuilders.termQuery("title", "手机"))
.highlighter(highlightBuilder)
.setFrom(0)// (page -1)* rows
.setSize(2)//rows
.addSort("id", SortOrder.ASC)//升序
.get();
//3.获取结果集
SearchHits hits = response.getHits();
//4.循环遍历结果获取高亮数据
System.out.println("获取高亮数据:>>>>" + hits.getTotalHits());
//5.存储高亮数据
for (SearchHit hit : hits) {
//6.打印
String sourceAsString = hit.getSourceAsString();//该数据不高亮
Article article = objectMapper.readValue(sourceAsString, Article.class);
Map<String, HighlightField> highlightFields = hit.getHighlightFields();
StringBuffer sb = new StringBuffer();
if (highlightFields != null && highlightFields.size() > 0) {
HighlightField highlightField = highlightFields.get("title");//获取title这个高亮数据
if (highlightField.getFragments() != null) {
for (Text text : highlightField.getFragments()) {
sb.append(text.string());
}
}
}
if (sb.length() > 0) {
article.setTitle(sb.toString());
}
System.out.println("文章的标题数据:" + article.getTitle());
}
}7.ElasticSearch常用编程操作ElasticsearchRestTemplate api (7.X版本)
1.判断索引是否存在
其实在前面写好Entity,启动项目如果索引不存在就会自动创建的,这里也可以通过Api的方式进行验证:
java
@Slf4j
@RestController
@RequestMapping("/rest")
public class RestTemplateController {
@Autowired
ElasticsearchRestTemplate elasticsearchRestTemplate;
@GetMapping("/indexExists")
public String indexExists() {
boolean r1 = elasticsearchRestTemplate.indexExists(UserEsEntity.class);
boolean r2 = elasticsearchRestTemplate.indexExists("user2");
// 创建索引
// elasticsearchRestTemplate.createIndex()
log.info("r1: {} , r2: {}", r1, r2);
return "success";
}
}2.新增文档数据
java
@GetMapping("/save")
public String save() {
UserEsEntity esEntity = new UserEsEntity(null, "张三", "男", 18, "1");
// 不要拿到自增的返回值
// UserEsEntity save = elasticsearchRestTemplate.save(esEntity);
// log.info(save.toString());
// 拿到自增的返回值
IndexQuery indexQuery = new IndexQueryBuilder()
// .withId(esEntity.getId())
.withObject(esEntity)
.build();
String id = elasticsearchRestTemplate.index(indexQuery, IndexCoordinates.of("user"));
log.info("添加的id:{} ", id);
// 批量添加
// List<UserEsEntity> list = new ArrayList<>();
// list.add(esEntity);
// list.add(esEntity);
// elasticsearchRestTemplate.save(list);
return "success";
}3.更新文档数据
其中根据条件批量修改需要使用RestHighLevelClient,直接注入即可:
java
@Autowired
RestHighLevelClient restHighLevelClient;
@GetMapping("/update")
public String update() throws IOException {
// 覆盖修改
// UserEsEntity esEntity = new UserEsEntity("W9MVD34BVYNyxUnr8cdE", "lisi", "男", 20, "1");
// elasticsearchRestTemplate.save(esEntity);
// UpdateQuery query = UpdateQuery.builder("W9MVD34BVYNyxUnr8cdE");
// 根据ID 修改某个字段
// Document document = Document.create();
// document.putIfAbsent("name", "wangwu2"); //更新后的内容
// UpdateQuery updateQuery = UpdateQuery.builder("W9MVD34BVYNyxUnr8cdE")
// .withDocument(document)
// .withRetryOnConflict(5) //冲突重试
// .withDocAsUpsert(true) //不加默认false。true表示更新时不存在就插入
// .build();
// UpdateResponse response = elasticsearchRestTemplate.update(updateQuery, IndexCoordinates.of("user"));
// log.info(response.getResult().toString()); //UPDATED 表示更新成功
// 根据条件批量更新 ,使用 RestHighLevelClient
// https://blog.csdn.net/weixin_34318272/article/details/88690004
// 参数为索引名,可以不指定,可以一个,可以多个
UpdateByQueryRequest request = new UpdateByQueryRequest("user");
// 版本冲突
request.setConflicts("proceed");
// 设置查询条件
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 并且 and
queryBuilder.must(QueryBuilders.termQuery("name", "lisi"));
queryBuilder.must(QueryBuilders.termQuery("sex", "男"));
request.setQuery(queryBuilder);
// 批次大小
request.setBatchSize(1000);
// 并行
request.setSlices(2);
// 使用滚动参数来控制“搜索上下文”存活的时间
request.setScroll(TimeValue.timeValueMinutes(10));
// 刷新索引
request.setRefresh(true);
// 更新的内容
request.setScript(new Script("ctx._source['name']='wangwu'"));
BulkByScrollResponse response = restHighLevelClient.updateByQuery(request, RequestOptions.DEFAULT);
log.info(response.getStatus().getUpdated() + ""); // 返回1 表示成功
return "success";
}4.删除文档数据
java
@GetMapping("/delete")
public String delete() {
// 根据id删除
// String r = elasticsearchRestTemplate.delete("XNMVD34BVYNyxUnr8cdE", IndexCoordinates.of("user"));
// log.info("r : {} ", r);
// 根据条件删除
BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 并且 and
queryBuilder.must(QueryBuilders.termQuery("name", "zhangsan"));
queryBuilder.must(QueryBuilders.termQuery("sex", "男"));
Query query = new NativeSearchQuery(queryBuilder);
elasticsearchRestTemplate.delete(query, UserEsEntity.class, IndexCoordinates.of("user"));
return "success";
}5.查询文档数据
java
@GetMapping("/search")
public String search() {
// 查询全部数据
// QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
// 精确查询 =
// QueryBuilder queryBuilder = QueryBuilders.termQuery("name", "lisi");
// 精确查询 多个 in
// QueryBuilder queryBuilder = QueryBuilders.termsQuery("name", "张三", "lisi");
// match匹配,会把查询条件进行分词,然后进行查询,多个词条之间是 or 的关系,可以指定分词
// QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "张三");
// QueryBuilder queryBuilder = QueryBuilders.matchQuery("name", "张三").analyzer("ik_max_word");
// match匹配 查询多个字段
// QueryBuilder queryBuilder = QueryBuilders.multiMatchQuery("男", "name", "sex");
// fuzzy 模糊查询,返回包含与搜索字词相似的字词的文档。
// QueryBuilder queryBuilder = QueryBuilders.fuzzyQuery("name","lisx");
// prefix 前缀检索
// QueryBuilder queryBuilder = QueryBuilders.prefixQuery("name","张");
// wildcard 通配符检索
// QueryBuilder queryBuilder = QueryBuilders.wildcardQuery("name","张*");
// regexp 正则查询
QueryBuilder queryBuilder = QueryBuilders.regexpQuery("name", "(张三)|(lisi)");
// boost 评分权重,令满足某个条件的文档的得分更高,从而使得其排名更靠前。
queryBuilder.boost(2);
// 多条件构建
// BoolQueryBuilder queryBuilder = QueryBuilders.boolQuery();
// 并且 and
// queryBuilder.must(QueryBuilders.termQuery("name", "张三"));
// queryBuilder.must(QueryBuilders.termQuery("sex", "女"));
// 或者 or
// queryBuilder.should(QueryBuilders.termQuery("name", "张三"));
// queryBuilder.should(QueryBuilders.termQuery("name", "lisi"));
// 不等于,去除
// queryBuilder.mustNot(QueryBuilders.termQuery("name", "lisi"));
// 过滤数据
// queryBuilder.filter(QueryBuilders.matchQuery("name", "张三"));
// 范围查询
/*
gt 大于 >
gte 大于等于 >=
lt 小于 <
lte 小于等于 <=
*/
// queryBuilder.filter(new RangeQueryBuilder("age").gt(10).lte(50));
// 构建分页,page 从0开始
Pageable pageable = PageRequest.of(0, 3);
Query query = new NativeSearchQueryBuilder()
.withQuery(queryBuilder)
.withPageable(pageable)
//排序
.withSort(SortBuilders.fieldSort("_score").order(SortOrder.DESC))
//投影
.withFields("name")
.build();
SearchHits<UserEsEntity> search = elasticsearchRestTemplate.search(query, UserEsEntity.class);
log.info("total: {}", search.getTotalHits());
Stream<SearchHit<UserEsEntity>> searchHitStream = search.get();
List<UserEsEntity> list = searchHitStream.map(SearchHit::getContent).collect(Collectors.toList());
log.info("结果数量:{}", list.size());
list.forEach(entity -> {
log.info(entity.toString());
});
return "success";
}设置查询返回的条数:
java
QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();
NativeSearchQuery query = new NativeSearchQueryBuilder()
.withQuery(queryBuilder )
.build();
// 允许返回条数设置 默认返回10000条
// 允许返回查询结果的total, search.getTotalHits()
searchQuery.setTrackTotalHits(true);
// 允许返回结果list的大小
searchQuery.setMaxResults(1000000);8.Spring Data ElasticSearch
8.1.Spring Data ElasticSearch简介
8.1.1什么是Spring Data
Spring Data是一个用于简化数据库访问,并支持云服务的开源框架。其主要目标是使得对数据的访问变得方便快捷,并支持map-reduce框架和云计算数据服务。 Spring Data可以极大的简化JPA的写法,可以在几乎不用写实现的情况下,实现对数据的访问和操作。除了CRUD外,还包括如分页、排序等一些常用的功能。
Spring Data的官网:http://projects.spring.io/spring-data/
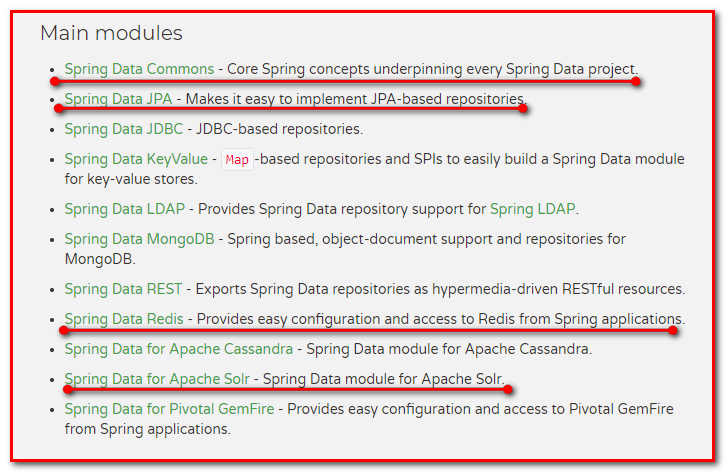
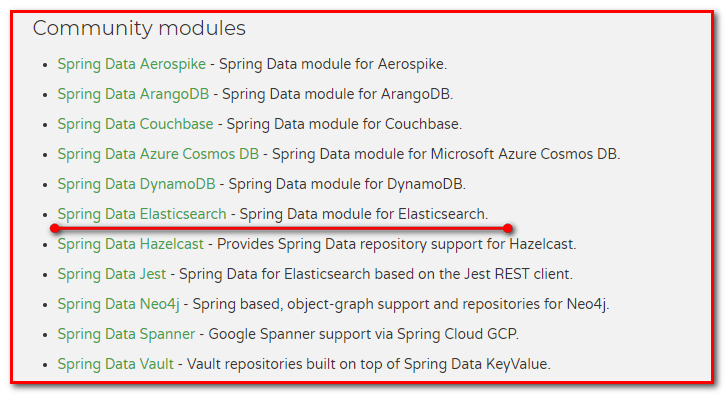
Spring Data常用的功能模块如下:
8.1.2什么是Spring Data ElasticSearch
Spring Data ElasticSearch 基于 spring data API 简化 elasticSearch操作,将原始操作elasticSearch的客户端JAVA API 进行封装 。Spring Data为Elasticsearch项目提供集成搜索引擎。Spring Data Elasticsearch POJO的关键功能区域为中心的模型与Elastichsearch交互文档和轻松地编写一个存储库数据访问层。官方网站:http://projects.spring.io/spring-data-elasticsearch/
Spring boot 集成spring data elasticsearch的方式来开发更加的方便和快捷
8.2.Spring boot starter data elasticsearch入门
8.2.1需求
需求: 保存Article
8.2.2代码实现
- 创建Maven工程(jar)
xml
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>- 创建pojo, 添加注解
java
/**
* @Document:放置到类上
* indexName = "blog1":表示索引的名称,(小写)
* type = "article":表示类型
* @Id:放置到字段id上
* 表示该字段的值存放到索引库的_id字段上,表示主键
* @Field:放置到字段上
* store = true:表示该字段的值存储到索引库
* index = true:表示该字段的值要建立索引用于搜索
* analyzer = "ik_smart":建立索引的时候使用什么分词器
* searchAnalyzer = "ik_smart":数据搜索的时候使用什么分词器(可以不写)
* type = FieldType.Text:存放字段的数据类型
*/
@Document(indexName = "blog03",type = "article")
public class Article implements Serializable {
@Id
private Long id;
@Field(index = true,searchAnalyzer = "ik_smart",analyzer = "ik_smart",store = true,type = FieldType.Text)
private String title;
@Field(index = true,searchAnalyzer = "ik_smart",analyzer = "ik_smart",store = true,type = FieldType.Text)
private String content;
public Article() {
}
public Article(long id, String title, String content) {
this.id = id;
this.title = title;
this.content = content;
}
public Long getId() {
return id;
}
public void setId(Long id) {
this.id = id;
}
public String getTitle() {
return title;
}
public void setTitle(String title) {
this.title = title;
}
public String getContent() {
return content;
}
public void setContent(String content) {
this.content = content;
}
@Override
public String toString() {
return "Article{" +
"id=" + id +
", title='" + title + '\'' +
", content='" + content + '\'' +
'}';
}
}- 创建Dao接口继承ElasticsearchRepository
java
public interface ArticleDao extends ElasticsearchRepository<Article,Long>{
}- springboot自动进行配置创建配置文件进行配置
- 测试
java
@SpringBootTest
@RunWith(SpringRunner.class)
public class EsApplicationTest03 {
@Autowired
private ElasticsearchTemplate elasticsearchTemplate;
@Autowired
private ArticleDao dao;
//创建索引
//创建映射
@Test
public void createMapping() {
elasticsearchTemplate.createIndex(Article.class);
elasticsearchTemplate.putMapping(Article.class);
}
}8.3.Spring Data ElasticSearch常见操作
8.3.1CRUD
- 新增
java
//创建文档/更新文档
@Test
public void createDocument() {
Article article = new Article(1L, "你的手机很好看", "您的手机真的很好看");
dao.save(article);
}
//批量创建文档
@Test
public void createDocumentS() {
List<Article> articles = new ArrayList<Article>();
for (long i = 0; i < 100; i++) {
Article article = new Article(i, "你的手机很好看" + i, "您的手机真的很好看" + i);
articles.add(article);
}
dao.saveAll(articles);
}- 删除
java
//删除文档
@Test
public void DeleteDocument() {
dao.deleteById(1L);
}- 更新; 没有id对应的数据,就是新增; 有当前id对应的数据,就是更新
java
//创建文档/更新文档
@Test
public void createDocument() {
Article article = new Article(1L, "你的手机很好看", "您的手机真的很好看");
dao.save(article);
}- 根据id查询
java
//根据ID查询
@Test
public void selectById() {
Article article = dao.findById(1L).get();
System.out.println(article);
}- 查询所有
java
//查询所有文档
@Test
public void SelectDocument() {
Iterable<Article> all = dao.findAll();
for (Article article : all) {
System.out.println(article);
}
}- 排序查询
java
@Test
//排序
public void fun07(){
Iterable<Article> iterable = articleDao.findAll( Sort.by(Sort.Order.asc("id")));
for (Article article : iterable) {
System.out.println(article);
}
}- 分页查询
java
@Test
public void selectAndPageSort() {
//设置分页条件
//参数1 当前页码 0 为第一页
//参数2 每页显示的行
//参数3 指定排序的条件 参数3.1 指定要排序的类型 参数3.2 指定要排序的字段
Pageable pageable = PageRequest.of(0, 2, new Sort(Sort.Direction.ASC, "id"));
Page<Article> articles = dao.findAll(pageable);
System.out.println("总记录数:" + articles.getTotalElements());
System.out.println("总页数:" + articles.getTotalPages());
//获取当前页的集合
List<Article> content = articles.getContent();
for (Article article : content) {
System.out.println(article);
}
}8.3.2自定义查询
- 常用查询命名规则
| 关键字 | 命名规则 | 解释 | 示例 |
|---|---|---|---|
| and | findByField1AndField2 | 根据Field1和Field2获得数据 | findByTitleAndContent |
| or | findByField1OrField2 | 根据Field1或Field2获得数据 | findByTitleOrContent |
| is | findByField | 根据Field获得数据 | findByTitle |
| not | findByFieldNot | 根据Field获得补集数据 | findByTitleNot |
| between | findByFieldBetween | 获得指定范围的数据 | findByPriceBetween |
| lessThanEqual | findByFieldLessThan | 获得小于等于指定值的数据 | findByPriceLessThan |
- 测试
java
public interface ArticleDao extends ElasticsearchRepository<Article,Long>{
//根据title模糊查询
List<Article> findByTitleLike(String title);
//根据title模糊查询,根据id降序
List<Article> findByTitleLikeOrderByIdAsc(String title);
//模块查询,排序加分页
Page<Article> findByTitleLikeOrderByIdAsc(String title,Pageable pageable);
}9.Kibana日常基本语句
1、全查询
代码如下:
json
GET device_tag/_search
{
"query":{
"match_all":{}
},
"size":1
}解释:
"query":指明了查询定义
"match_all":"match"表明查询类型,"match_all"表示查询的是指定索引中的所有文档
"size":传入参数"size":0表示不显示搜索结果,当用于聚合时,设置值0,则响应结果中只会看到聚合结果,"size"未指定时,默认值为10,当然,当需要对输出结果进行分页时,也需要用到"size",同时结合"from"
具体如下:
json
GET device_tag/_search
{
"query":{
"match_all":{}
},
"from":2
"size":2
}分页查询:通过from(表示从第几条数据开始看,0表示从第一条开始看),size(表示每一页总计数据条数),故如果要看第2页,则from的值满足(页码-1)*每页数据条数,即为from:2
如果要对查询结果进行排序处理,则需要用到"sort",通常输出结果为整个源文档,当需要保留多个字段,可以使用"_source": ["device_name","device_id"]来实现,当只看某一个字段时,直接用"_source": "device_id"即可,只看一个字段时,具体代码如下:
json
GET device_tag/_search
{
"query":{
"match_all": {}
},
"from":2,
"size":2,
"_source": "device_id",
"sort":{
"device_price":{
"order":"desc"
}
}
}2、主键查询
对于主键查询,顾名思义,依靠主键的信息进行查询,例如,在device_tag里的主键为id,若只要查看一台设备,可用以下方法:
json
GET device_tag/_doc/88886665555
{
"query":{
"match_all":{}
}
}3、条件查询
条件查询 ?q=tag_road : "光明路",q表示查询,这里和上面的_doc/的区别是这里是任意一个对象,_doc/是主键查询,可用以下方法:
json
GET device_tag/_search?q=tag_road : "光明路"
{
"query":{
"match_all":{}
}
}条件查询中,条件也可以放到"match"里面,可用以下方法:
json
GET device_tag/_search
{
"query":{
"match":{
"tag_road":"光明路"
}
}
}4、布尔查询
布尔查询是指使用布尔逻辑把基本查询组合成复杂查询("bool":表示条件,嵌套在"query"内部,表示查询内容需要满足的条件)
"must":表示同时满足所有条件,"must"用了[]表示数组
"should":表示只需满足其中一个条件即可
"should":表示只需满足其中一个条件即可
"must_not":表示一个条件都不满足
"match":用法和前面一致,这里特别点在于每一个条件用一个"match"单独表示
a."must"
筛选出"tag_road"为"光明路",同时"online_state_value"为"断线"的所有设备,可用以下写法:
json
GET device_tag/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"tag_road":"光明路"
}
},
{ "match":{
"online_state_value":"断线"
}
}
]
}
}
}b."should"
筛选出"tag_road"为"光明路"或者"online_state_value"为"断线"的所有设备,可用以下写法:
json
GET device_tag/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"tag_road":"光明路"
}
},
{ "match":{
"online_state_value":"断线"
}
}
]
}
}
}c."must_not"
筛选出"tag_road"不为"光明路",同时"online_state_value"不为"断线"的所有设备,可用以下写法:
json
GET device_tag/_search
{
"query":{
"bool":{
"must_not":[
{
"match":{
"tag_road":"光明路"
}
},
{ "match":{
"online_state_value":"断线"
}
}
]
}
}
}d."bool"查询中将"must"/"should"/"must_not"组合使用
筛选出"tag_road"为"光明路",同时"online_state_value"不为"断线"的所有设备,可用以下写法:
json
GET device_tag/_search
{
"query":{
"bool":{
"must":[
{
"match":{
"tag_road":"光明路"
}
}],
"must_not":[
{ "match":{
"online_state_value":"断线"
}
}
]
}
}
}5、范围查询(条件过滤):范围查询用"filter"(过滤器)-"range"
gt,gte,lt,lte缩写的含义:【gt: greater than 大于】【gte: greater than or equal 大于等于】【lt: less than 小于】【lte: less than or equal 小于等于】
下面以字段"device_price"的范围为[18000,20000]为例,具体如下:
json
GET device_tag/_search
{
"query":{
"bool":{
"should":[
{
"match":{
"tag_road":"光明路"
}
},
{ "match":{
"online_state_value":"断线"
}
}
],
"filter": {
"range": {
"device_price": {
"gte": 18000,
"lte": 20000
}
}
}
}
}
}注意点:如果不是布尔查询,新传入的参数直接和"query"构成并列关系,当为布尔查询时,新传入的参数放进"bool"内部,与"must"或者"should"构成的数组并列
6、全文检索&完全匹配&高亮查询
全文检索&完全匹配
前提:在进行全文检索前,先要明白导入数据即存储过程分词器的原理以及查询数据分词的原理
分词:分词是将文本转换成一系列单词的过程,也可以叫文本分析,在ES里面称为Analysis:
从数据出发,通俗理解
a.首先对于不同的字段要先确定其类型是keyword还是text,可以直接执行GET device_tag,在输出结果界面直接Crtl+F查找字段来确定:
如果类型为keyword,则说明字段的存储并未进行分词操作,一般这种用于需要精确检索的字段
如果类型为text,则说明字段存储时进行了分词操作,一般这种用于需要模糊检索的字段
b.确定好字段类型后,要处理的则是查询过程,查询过程主要看的是term和match之间的差别
term:完全匹配,也即是精确查询,通俗的说就是搜索前不会再对搜索词进行分词拆解,如果搜索好几类词的公 共部分,则这些词都会被搜索出来。虽然term不会对搜索词进行分词,但是包含搜索词的所有部分都会被查出来,并不需要搜索词和原始录入词完全一致。term并不能通过"terms":{[,]}来进行对由多个词构成的词组查询,这种写法实际达成的是只要满足其中一个就被查询出来的效果,如果要多个词组组合查询需要用"bool"和"must"结合查询
match:match和term的区别在于match在进行搜索时,会先进行分词拆分,然后再进行匹配,故原始字段只要包含搜索词中的一个分词结果就行
match_phrase:如果为短语搜索,要求所有的分词必须同时出现在文档中,同时要求位置也一致
涉及到分词,这里关键步骤如下:
1、通过GET device_tag/先查看每一个字段类型是text还是keyword,如果是keyword,存储时不会对其分词,如果是text,则会分词
2、对于存储会分词的text类型,通过
json
GET device_tag_20220314/_analyze
{
"field": "{device_name}",
"text":"4号楼88号机床"
}来查看分词结果,其中device_tag_20220314为索引,类似于数据库,这样便可以指定看device_tag里device_name的分词结果("_index" : "device_tag_20220314"),
3、
----------term----------
json
GET device_tag/_search
{
"query":{
"term":{
"device_name": "机床"
}
}
}这样可以查询出结果,用term只需要查询内容为原始数据分词结果的任一子集即可,并且也只能是其中一个子集
----------match----------
json
GET device_tag/_search
{
"query":{
"match":{
"device_name": "机床哈哈哈哈哈呵呵呵呵呵"
}
}
}这样可以查询出结果,用match相当于只要查询内容与原始数据分词结果有交集即可
高亮查询:
json
GET device_tag/_search
{
"query":{
"term":{
"device_name": "机床"
}
},
"highlight":{
"fields":{
"device_name": {}
}
}
}6、聚合查询
聚合可以理解等同于SQL里的Group By和SQL的聚合函数,执行返回命中文档的搜索,同时返回与搜索结果分离的聚合结果
a.分组
json
GET device_tag/_search
{
"aggs":{
"device_price_group":{
"terms":{
"field": "device_price"
}
}
},
"size":0
}注释:
json
GET device_tag/_search
{
"aggs":{ //"aggs"的作用是聚合操作
"device_price_group":{ //"device_price_group"为分组名称。可以任意取
"terms":{ //"terms"表示分组,分组计数
"field": "device_price" //这里为确定分组的字段
}
}
},
"size":0 //"size":0表示不显示搜索结果,只在响应结果中看到聚合结果
}b.求平均值
json
GET device_tag/_search
{
"aggs":{
"device_price_avg":{
"avg":{
"field": "device_price"
}
}
},
"size":0
}