Appearance
培训视频
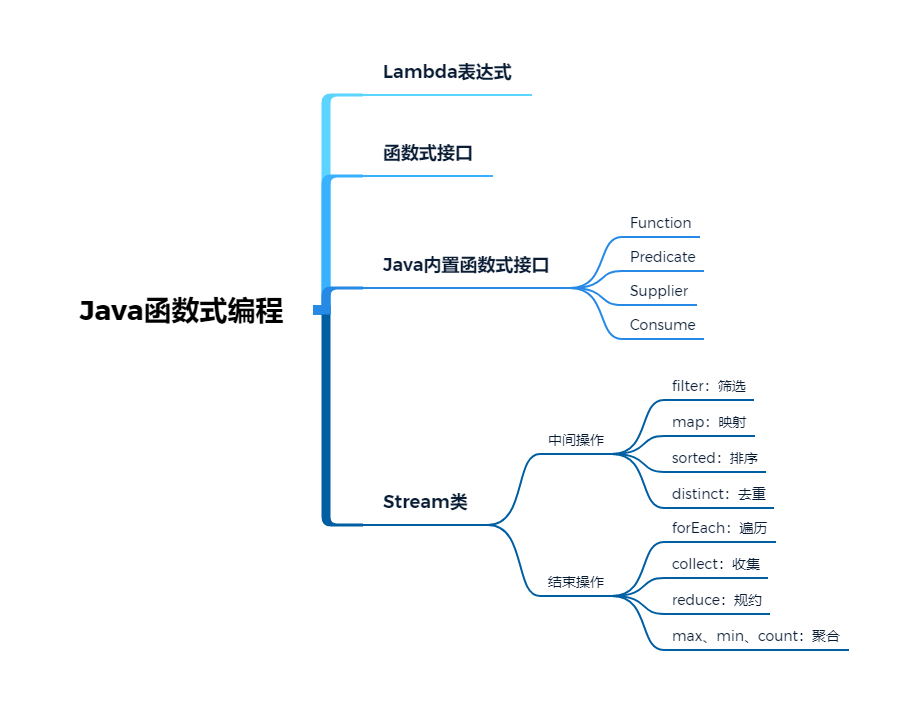
函数式编程
目的:了解函数式编程范式的核心原则以及如何在 Java 编程语言中使用。以及介绍一些高级函数式编程技术,这将帮助我们了解Java中的函数式编程的好处。
什么是函数式编程?
函数式编程是一种,抽象度很高的编程范式。还有两种编程范式我们很熟悉:面向过程编程、面向对象编程。
函数式编程与面向对象或面向过程独特的地方在于,它的编程思想。
严格上来讲,函数式编程中的“函数”,并不是指我们编程语言中的“函数”概念,而是指数学“函数”或者“表达式”(例如:y=f(x))。可以理解为一种映射关系。
对比一下这三种范式:
- 面向对象: 类是一等公民,万物皆对象,函数内部涉及的变量,可以共享类变量。
- 面向过程: 以过程为中心,函数内部涉及的变量,可以共享全局变量。
- 函数式编程: 函数是一等公民,函数内部涉及的变量,都是局部变量。
举个例子:
java
// 有状态函数: 执行结果依赖b的值是多少,即便入参相同,
// 多次执行函数,函数的返回值有可能不同,因为b值有可能不同。
int b;
int increase(int a) {
return a + b;
}
// 无状态函数:执行结果不依赖任何外部变量值
// 只要入参相同,不管执行多少次,函数的返回值就相同
int increase(int a, int b) {
return a + b;
}可以看到,函数式编程中的函数是无状态的。它的执行结果只与入参有关,跟其他任何外部变量无关,同样的入参,不管怎么执行,得到的结果都是一样的。这实际上就是数学函数或数学表达式的基本要求。
总结一下:
- 面向对象的编程单元是类或对象
- 面向过程的编程单元是函数
- 函数式编程的编程单元是无状态函数。
Java对函数式编程的支持
Java为函数式编程引入了三个新的语法概念:Stream类、Lambda表达式和函数接口:
Stream类用来支持通过“.”级联多个函数操作的代码编写方式;- 引入
Lambda表达式的作用是简化代码编写; - 函数接口的作用是让我们可以把函数包裹起来,实现把函数当做参数一样来使用
Lambda表达式
Lambda 表达式是 Java 8 中重要的新特性之一,它可以让我们的 Java 代码变得更加简洁。
Lambda 可以理解为:可传递的匿名函数的一种简洁表达方式。
举个例子,在不使用 Lambda 表达式之前,线程创建了一个 Runnable 子类实例我们可以这么写:
java
// 初始化线程实例
Thread thread = new Thread(new Runable() {
@Override
public void run() {
System.out.println("...")
}
});这是一种匿名内部类的写法,线程创建了一个 Runnable 子类实例。
上面的代码如果用 Lambda 表达式就可以变得十分简洁:
java
Thread thread = new Thread(() -> { System.out.println("..."); });这里对 Lambda 的语法进行一些简单的说明:
- () 括号里面是参数列表,如果只有一个参数还可以写为:
a -> System.out.println(a) - -> 箭头为固定写法;
System.out.println("...")为函数主体,如果有多条语句要用花括号包裹起来,比如:
java
(a, b) -> {
int sum = a + b;
return sum;
}使用 Lambda 表达式的优点:
- 避免内部类定义过多
- 让代码看起来更整洁
- 去掉一堆没有意义的代码,只留下核心逻辑
这就会引出一个问题:并不是所有的匿名内部类都可以使用 Lambda 表达式简化,那么有什么条件?
函数式接口
函数式接口是只定义了一个抽象方法的接口。举个例子:
java
@FunctionalInterface
public interface Runnable {
public abstract void run();
}注意Java 8中允许存在默认方法(default),哪怕有很多默认方法,只要有且仅有一个抽象方法,那么这个接口仍然是函数式接口。
只有函数式接口,才能使用 Lambda 表达式。
函数式接口通常在类上有一个注解 @FunctionalInterface
这个注解就一个作用:一旦使用了该注解标注接口,Java 的编译器将会强制检查该接口是否满足函数式接口的要求:“确实有且仅有一个抽象方法”,否则将会报错。
也就是说,即使不使用该注解,只要一个接口满足函数式接口的要求,那它仍然是一个函数式接口,使用起来都一样。该注解只起到标记接口指示编译器对其进行检查的作用。
Java内置函数式接口
除了之前提到的 Runnable 之外,Java 语言内置了一组为常见场景用例设计的函数式接口,这样就不必每次用到 Lambda 表达式、Stream 操作的时候还要自己去创建函数式接口
这些接口位于java.util.function包中,这里列出几个常用的:
| name | type | result | desc |
|---|---|---|---|
| Consumer | Consumer | T -> void | 接收 T 对象,不返回值 |
| Predicate | Predicate | T -> boolean | 接收 T 对象并返回 boolean |
| Function | Function<T, R> | T -> R | 接收 T 对象,返回 R 对象 |
| Supplier | Supplier | void -> T | 提供 T 对象(例如工厂),不接收值 |
Stream类
Stream 是 Java 8 中集合数据处理的利器,很多本来复杂、需要写很多代码的方法比如过滤、分组等操作,使用 Stream 就可以在一行代码搞定。
Collection接口提供了 stream()方法,让我们可以在一个集合方上便的使用 Stream API 来进行各种操作。
我们执行的任何操作都不会对源集合造成影响,可以同时在一个集合上提取出多个 Stream 进行操作。
简单来说,流是对数据源的包装,它允许我们对数据源进行聚合操作,并且可以方便快捷地进行批量处理。
中间操作和终结操作
一个流的处理链由一个源(source),0 到多个中间操作(intermediate operation)和一个终结操作(terminal operation)完成。
- 源: 源代表
Stream中元素的来源,例如某个集合对象。 - 中间操作: 中间操作,在一个流上添加的处理器方法,他们的返回结果是一个新的流。这些操作是延迟执行的,在终结操作启动后才会开始执行。
- 终结操作: 终结流操作是启动元素内部迭代、调用所有处理器方法并最终返回结果的操作。
举个例子:
java
public class StreamExamples {
public static void main(String[] args) {
List<String> stringList = Arrays.asList("ONE", "TWO", "THREE");
long count = stringList
.stream()
.map(String::toLowerCase)
.count();
}
}map() 方法的调用是一个中间操作。它只是在流上设置一个 Lambda 表达式,将每个元素转换为小写形式。而对 count() 方法的调用是一个终结操作。此调用会在内部启动迭代,开始流处理,这将导致每个元素都转换为小写然后计数。
流的中间操作
Stream API 的中间操作作用是转换或者过滤流中元素。当把中间操作添加到流上时,会得到一个新的流作为结果。比如之前的例子:
java
List<String> stringList = Arrays.asList("ONE", "TWO", "THREE");
Stream<String> stream = stringList.stream();
// 返回一个新的Stream实例,所以可以将中间操作串联成一个调用链
Stream<String> streamStream = stream.map(String::toLowerCase);常用的流中间操作
- map:映射
- filter:筛选
- distinct:去重
- sorted:排序
map
map() 方法将一个元素映射成另一个对象,接受一个 Function 函数式接口,通过原始数据元素映射出新的类型。
java
<R> Stream<R> map(Function<? super T, ? extends R> mapper);例如一个字符串列表,map() 可以计算每个字符串的长度,映射为一个 int 列表:
java
private void testMap() {
List<String> stringList = Arrays.asList("ONE", "TWO", "THREE");
// map使用
Object[] lengths = stringList.stream().map(String::length).toArray();
System.out.println("map:" + Arrays.toString(lengths));
}Java 在此基础上还封装了其他的 map:
- mapToInt:将元素转换成 int 类型,在
map方法的基础上进行封装。 - mapToLong:将元素转换成 Long 类型,在
map方法的基础上进行封装。 - mapToDouble:将元素转换成 Double 类型,在
map方法的基础上进行封装。
filter
用于条件筛选过滤,筛选出符合条件的数据。接受一个 Predicate,filter() 为流中的每个元素调用 Predicate。如果元素要包含在 filter() 返回结果的流中,则 Predicate 应返回 true。如果不应包含该元素,则 Predicate 应返回 false。
java
Stream<T> filter(Predicate<? super T> predicate);过滤长度大于等于3的字符串:
java
private void testFilter() {
List<String> stringList = Arrays.asList("ONE", "TWO", "THREE");
// filter 过滤长度大于等于3的字符串
Object[] lengths = stringList.stream().filter(v -> v.length() <= 3 ).toArray();
System.out.println("filter:" + Arrays.toString(lengths));
}distinct
distinct() 会返回一个仅包含原始流中不同元素的新 Stream 实例,任何重复的元素都将会被去掉。
源码:
java
Stream<T> distinct();去掉相同的元素:
java
private void testDistinct() {
List<String> stringList = Arrays.asList("ONE", "ONE", "THREE");
// 去除相同元素
Object[] lengths = stringList.stream().distinct().toArray();
System.out.println("distinct:" + Arrays.toString(lengths));
}sorted
有两个重载,一个无参数,另外一个有个 Comparator类型的参数。
java
// 按照自然顺序进行排序,只适合比较单纯的元素,比如数字、字母等
Stream<T> sorted();
// 有参数可以根据需要自定义排序规则
Stream<T> sorted(Comparator<? super T> comparator);具体使用:
java
private void testSorted() {
// 无参数sorted
List<Integer> intList = Arrays.asList(2, 42, 14, 6);
Object[] ints = intList.stream().sorted().toArray();
System.out.println("无参数sorted:" + Arrays.toString(ints));
// 有参数sorted
List<String> stringList = Arrays.asList("ONE", "ONE_TWO", "THREE");
Object[] strings = stringList.stream().sorted(Comparator.comparing(String::length)).toArray();
System.out.println("有参数sorted:" + Arrays.toString(strings));
}流的终结操作
Stream 的终结操作通常会返回单个值,一旦一个 Stream 实例上的终结操作被调用,流内部元素的迭代以及流处理调用链上的中间操作就会开始执行,当迭代结束后,终结操作的返回值将作为整个流处理的返回值被返回。
java
private void testStream1() {
List<String> stringList = Arrays.asList("ONE", "TWO", "THREE");
long count = stringList.stream()
.map(String::toLowerCase)
.count();
}Stream 的终结操作 count() 被调用后整个流处理开始执行,最后将 count() 的返回值作为结果返回,结束流操作的执行。这也是为什么把他们命名成流的终结操作的原因。
常用的终结操作
- forEach :遍历
- collect :手机
- reduce :规约
- max、min、count :聚合
- find、match :匹配
forEach
forEach() 用于迭代 List 的元素。它会启动 Stream 中元素的内部迭代,并将 Consumer 应用于 Stream 中的每个元素。 注意 forEach() 方法的返回值是 void。
java
void forEach(Consumer<? super T> action);示例:
java
private void testForeach() {
List<String> stringList = Arrays.asList("ONE", "TWO", "THREE");
stringList.stream().forEach(System.out::println);
}collect
collect() 方法被调用后,会启动元素的内部迭代,并将流中的元素收集到集合或对象中。
java
<R, A> R collect(Collector<? super T, A, R> collector);collect() 方法将收集器:Collector 作为参数。
java
private void testCollect() {
List<String> stringList = Arrays.asList(
"One flew over the cuckoo's nest",
"To kill a mucking bird",
"Gone with the wind");
List<String> collect = stringList.stream()
.map(String::toUpperCase)
.collect(Collectors.toList());
System.out.println("collect:" + collect);
}在上面的示例中,使用的是 Collectors.toList() 返回的 Collector 实现。这个收集器把流中的所有元素收集到一个 List 中去。
关于 Collectors 有兴趣的可以私下了解,这里不做扩展。
reduce
reduce() 方法,是 Stream 的一个聚合方法,它可以把一个 Stream 的所有元素按照聚合函数聚合成一个结果。reduce() 方法接收一个函数式接口 BinaryOperator 的实现,它定义的一个**apply()**方法,负责把上次累加的结果和本次的元素进行运算,并返回累加的结果。
java
Optional<T> reduce(BinaryOperator<T> accumulator);reduce() 方法的返回值同样是一个 Optional 类的对象,所以在获取值前别忘了使用 ifPresent() 进行检查。
java
private void testReduce() {
List<String> stringList = Arrays.asList(
"One flew over the cuckoo's nest",
"To kill a mucking bird",
"Gone with the wind");
stringList.stream().reduce((v, com) -> com + " + " + v).ifPresent(System.out::println);
}max、min、count
min() 方法返回 Stream 中的最小元素,max() 方法会返回 Stream 中的最大元素,count() 方法调用后,会启动 Stream 中元素的迭代,并对元素进行计数。
java
private void testMinMaxCount() {
List<Integer> intList = Arrays.asList(2, 42, 14, 112, 6);
intList.stream().min(Integer::compareTo).ifPresent(System.out::println);
intList.stream().max(Integer::compareTo).ifPresent(System.out::println);
System.out.println(intList.stream().count());
}