Appearance
问题收集4
1、命名是中文编程,这个是业务类型的命名(违反编程规则)
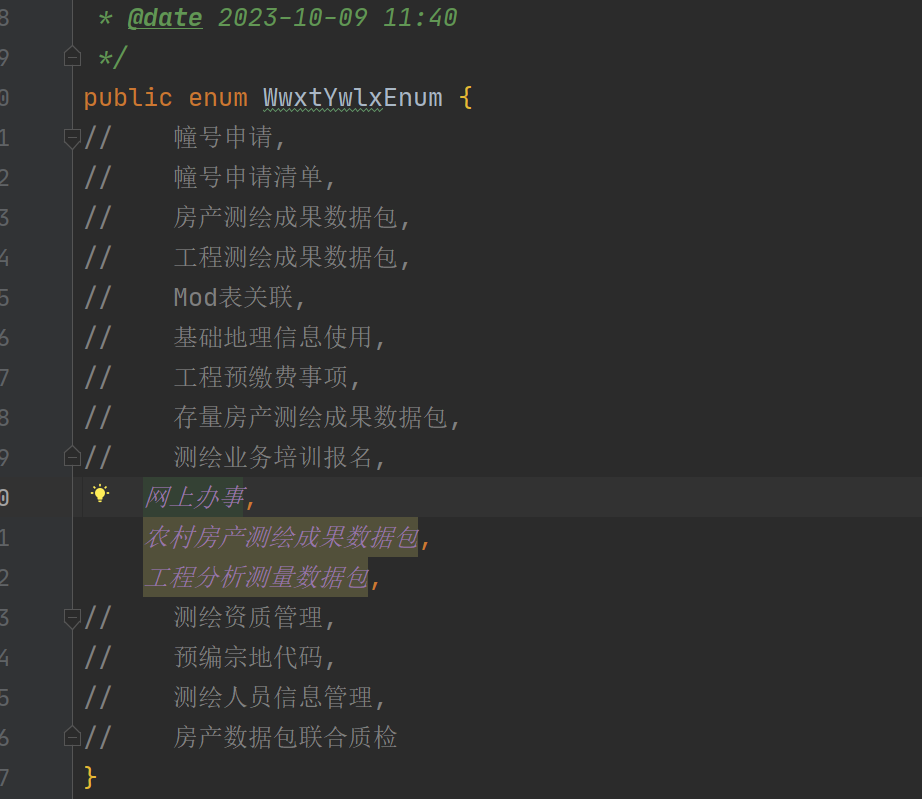
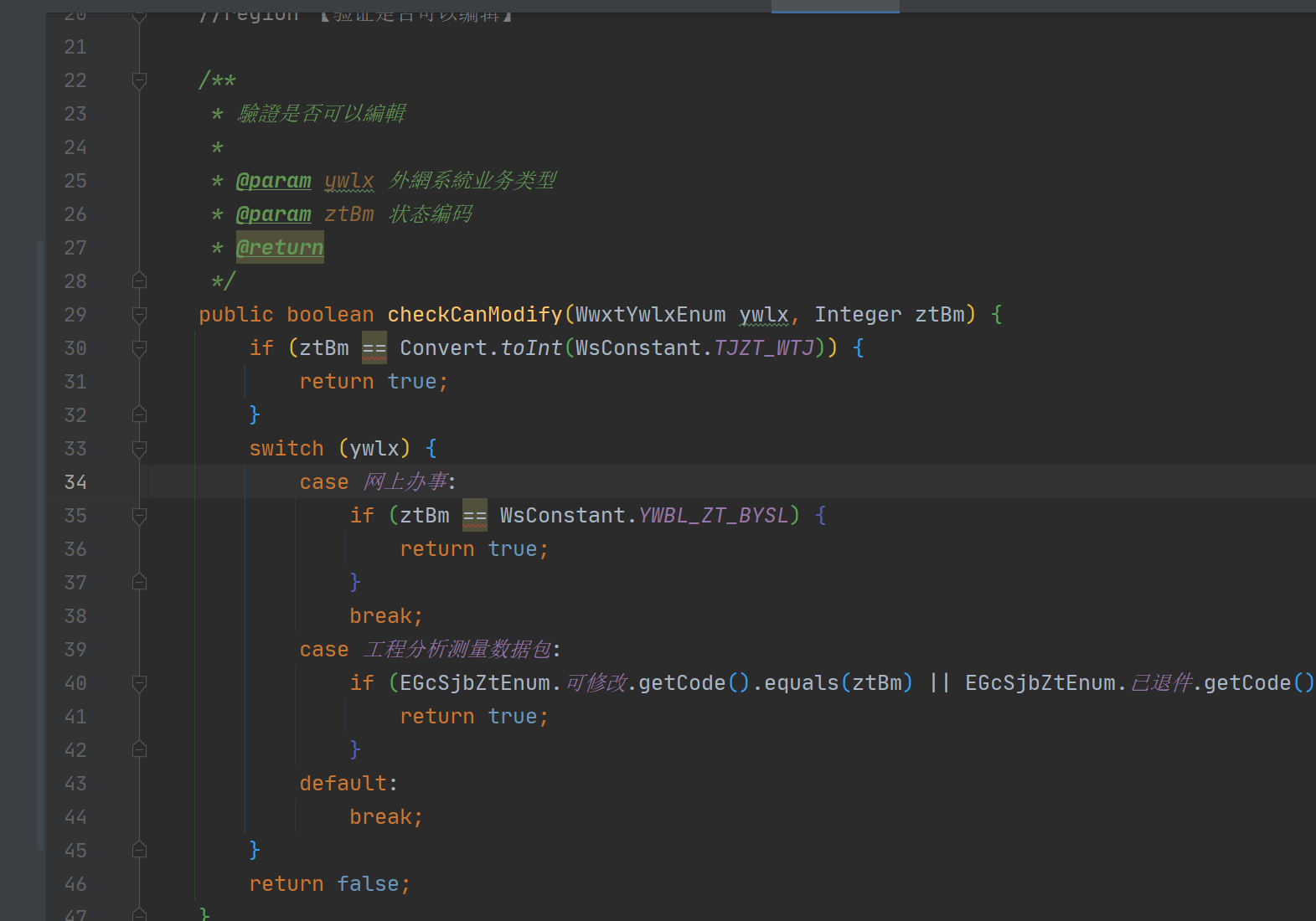
2、这里中文命名编程,这个是存变量的命名,讨论是否允许这样写,建议写英文,例如提交SUBMIT(违反编程规则)
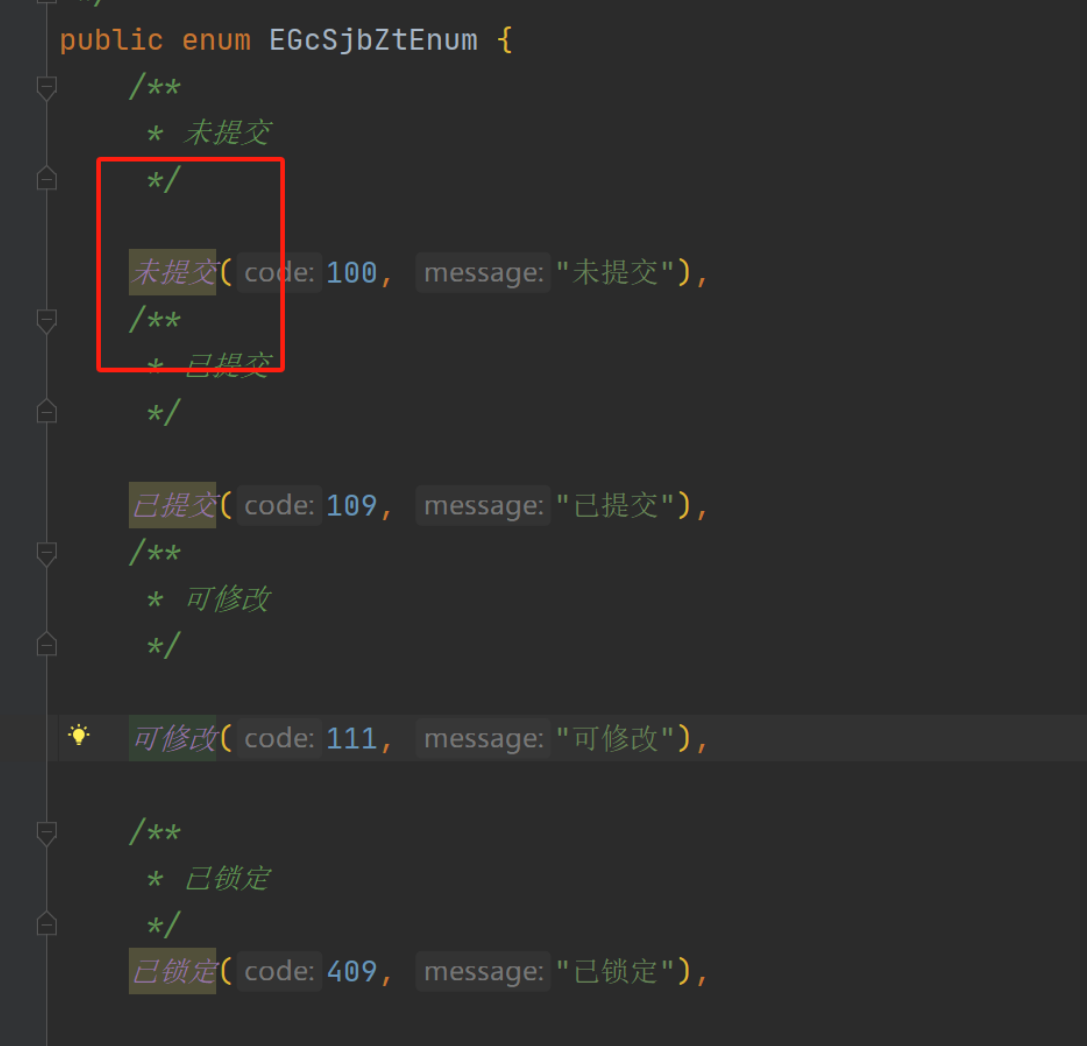
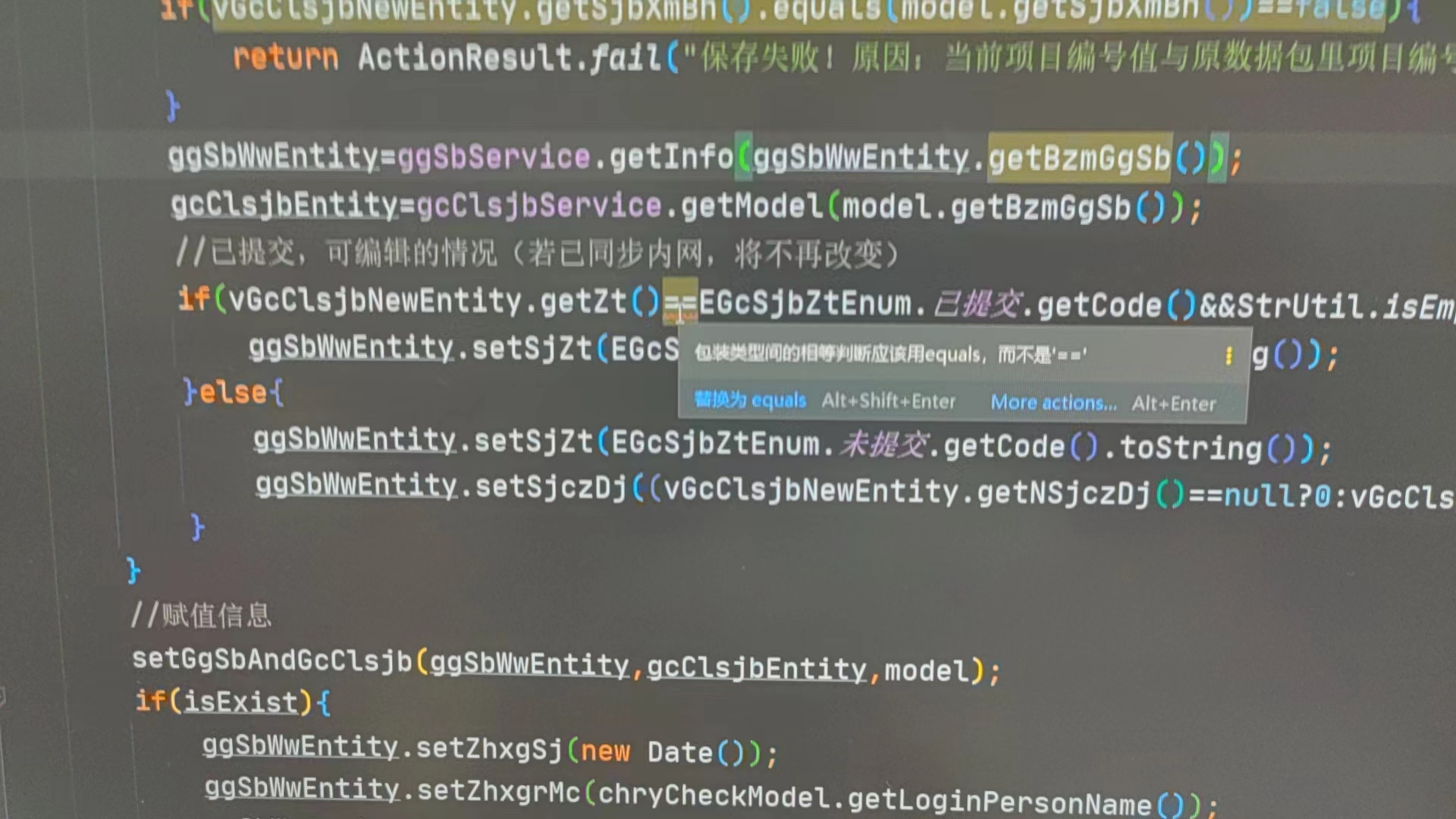
3、Integer和Integer判断相等 不能用== ,Integer是对象,不能按int基本数据类型判断;
对基数类型和包装类型没了解

穿插补充浮点型(跟整数使用不一样)



4、@TableId与 @TableField不能两个都配置,都配置的时候会是@TableId起作用
如下配置有2个缺点
- 系统启动的时候会去检测这种非法的,导致启动速度变慢
- 容易引起误解,对应的数据库字段BZM_V_GC_CLSJB_NEW是 @TableField("BZM_V_GC_CLSJB_NEW")在起作用,然后不是,是@TableId默认是根据类属性字段转驼峰映射数据库刚好对上
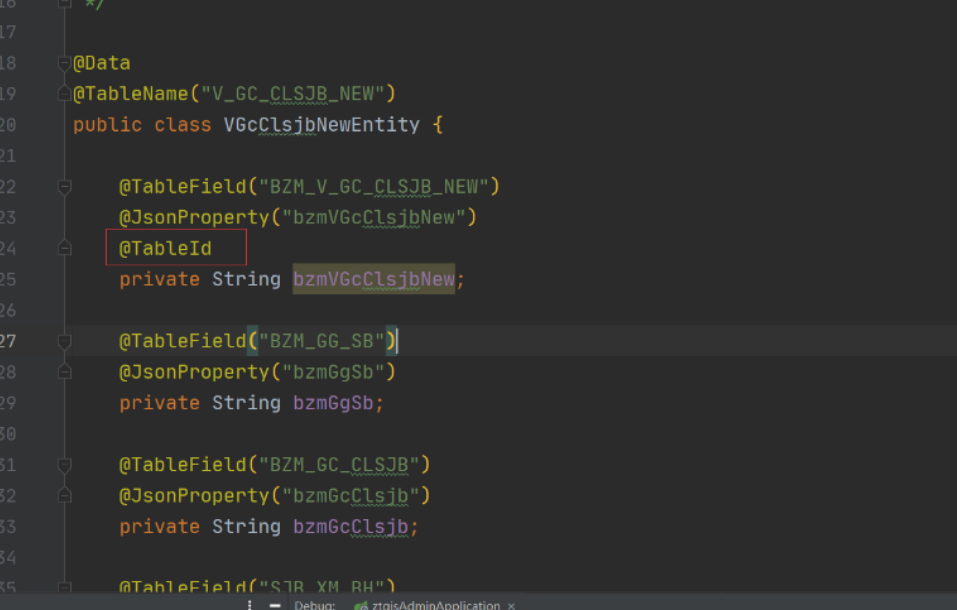
- 不能全部配置@TableField,而@TableId一个都没有
5、拼凑查询语句对外暴露(违反3层规则)
- 这个违反了3层框架结构,将查询语句对外暴露各自拼凑,等于架空了Service层(mvc的时是dao专门负责拼查询语句)
- 对外暴露会某个表的查询语句将出现在任何地方,降低业务代码可读性
如写成具体的方法名调用,有利于其他人根据方法名和注释查看方法的在做什么,也可以集中维护查询语句 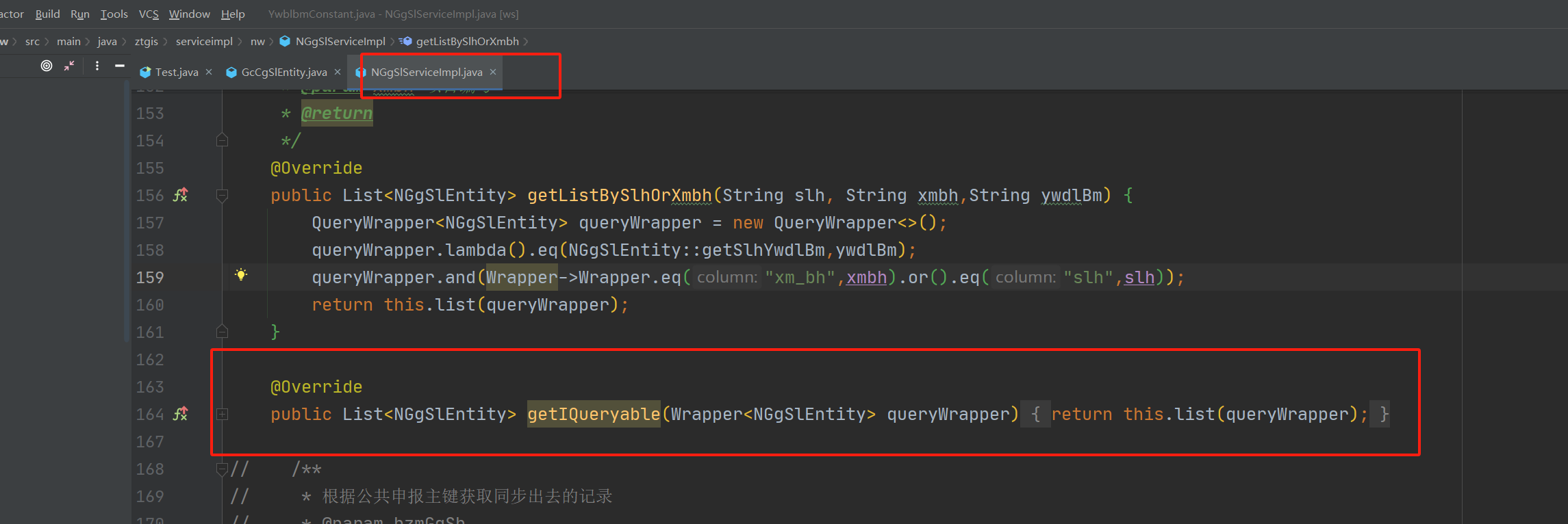
6、目前发现很多本不需要try catch,但写上了try catch
所到来的影响如下
- 吃了异常导致框架捕获不到异常,又没有手动打印log.error,导致报错时无法排查具体报错原因

- 删除,插入,或者更新了数据库,但catch的时候吃了异常没有重新抛出新的异常 导致事务无法回滚
(目前也有通过TransactionAspectSupport.currentTransactionStatus().setRollbackOnly()回滚的,未确定多数据库回滚是否能成功)
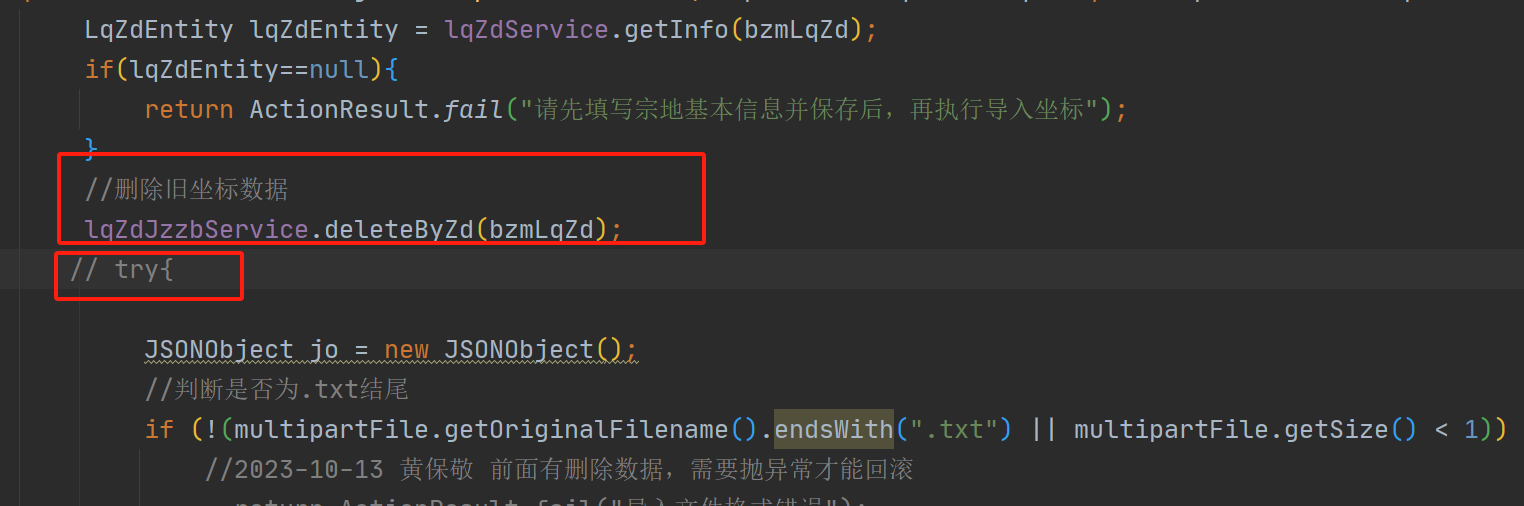
- 建议:try catch 需要有目的性 ,不能任意catch异常,需注释catch的原因,方便其他人接手的时候能知道
例如:按单同步数据的时候,回滚后再吃了异常,目的是为了下一单可以继续同步
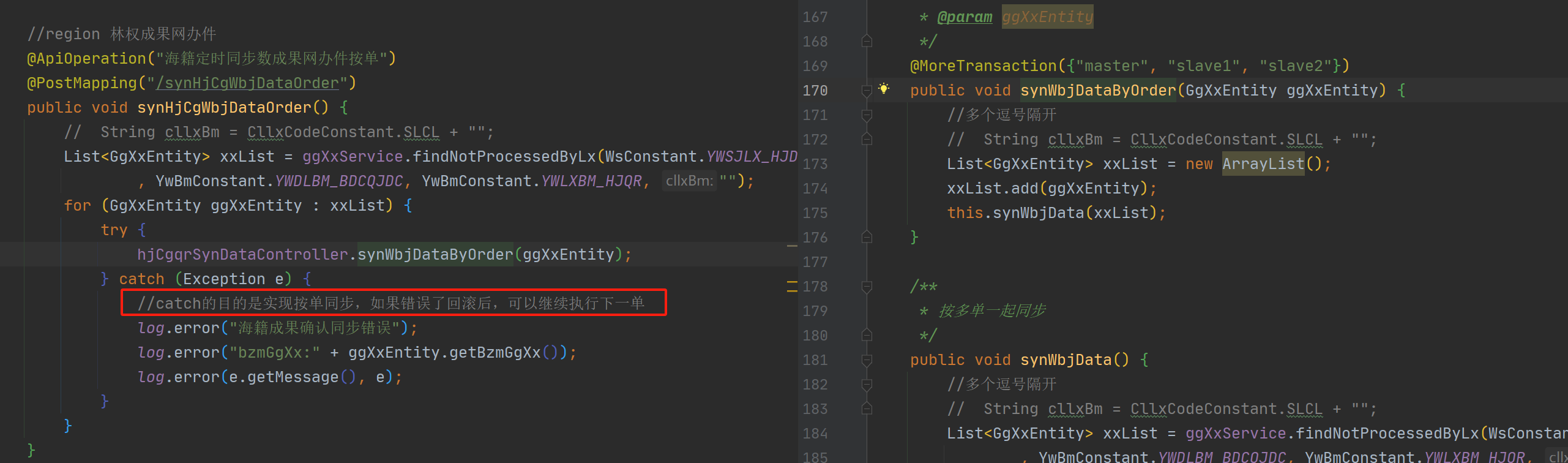
7、catch后重新抛出新提示语继续是原始异常信息,失去catch的意义
正常是如下两种做法
1、手动打印错误信息,改写用户能看懂提示语(不携带Exception异常信息)
2、不刻意catch,由框架统一报Exception错误信息
7.1、反例 一半自己的提示语,一半系统原始异常信息,这时catch与不catch对用户没区别 ,且没打印错误信息,导致无法排查问题
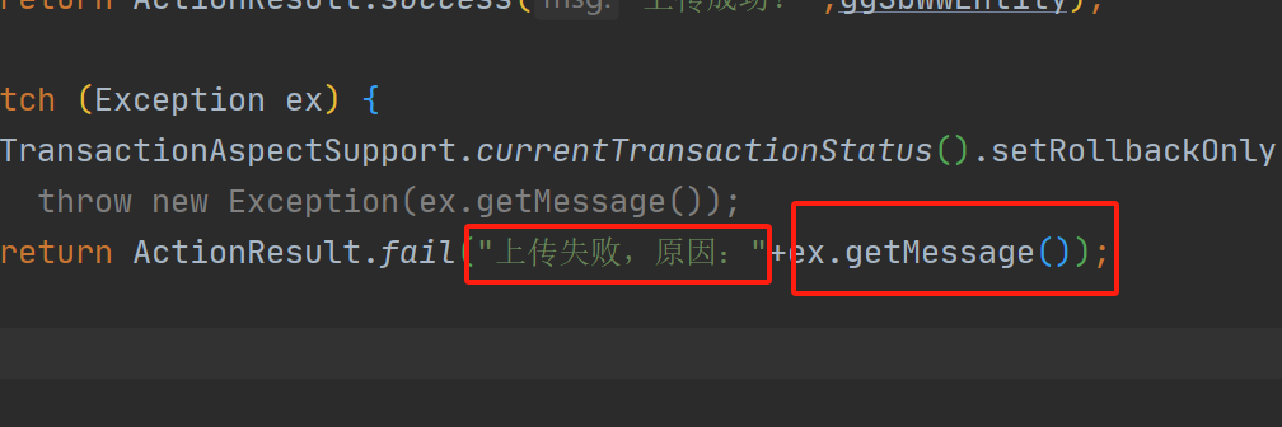
7.2、正例 改成用户能完全看懂提示语(针对用户),手动打日志(用户反馈异常时有错误日志可查) ,上面的做法1
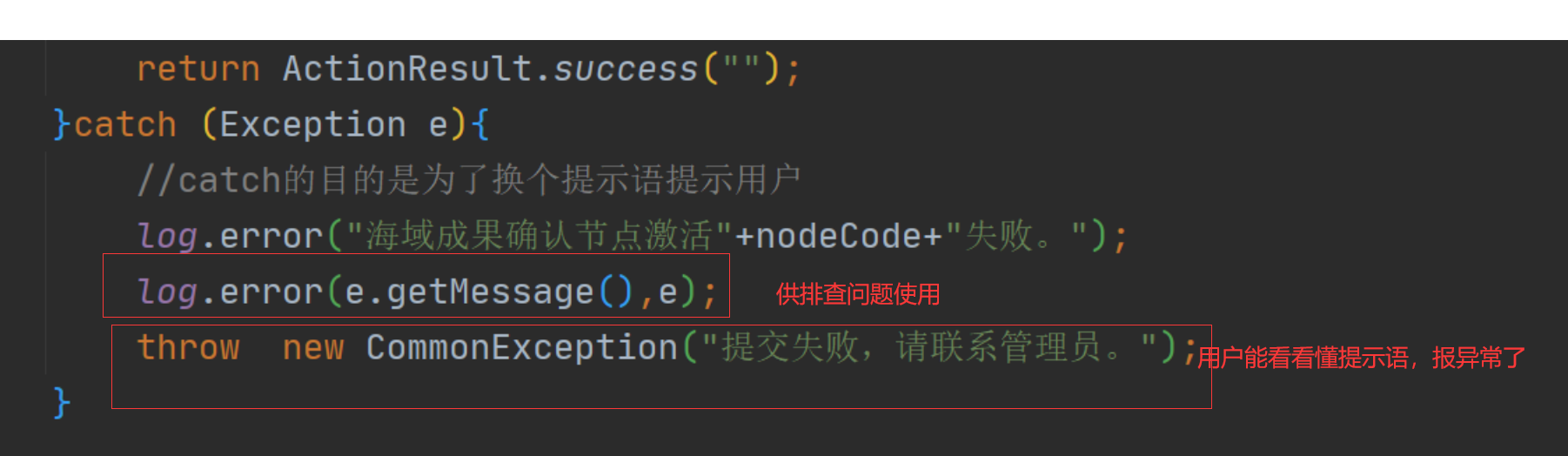
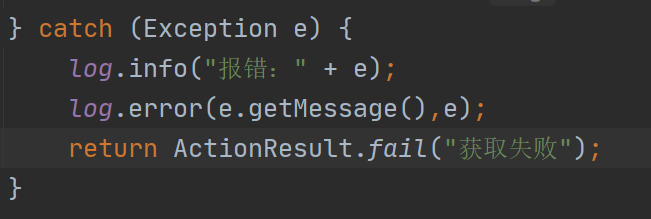
8、事务回滚问题
return ActionResult.fail("导入文件格式错误");是与前端约定一个数据结构体,对java来说不是异常,是无法事务回滚,应改为抛出一个异常
9、对于用户上传文件或者其他路径过来的需要解析的数据
用户需求场景: 用户需求1:因用户不小心多输入了一个空格,肉眼没看出来,要求兼容这种格式 用户需求2:逗号的字段顺序调整

相关多处使用地方都是使用txt的原始数据,导致用户提出的需求要对txt内容做处理,需要到处修改
建议:拿到txt数据后,可以转换成系统自己的字段数据xxxModel的dataList列表,后面相关的使用使用dataList 好处,不管用户怎么修改,只需要修改用户填的数据跟dataList做对应处理
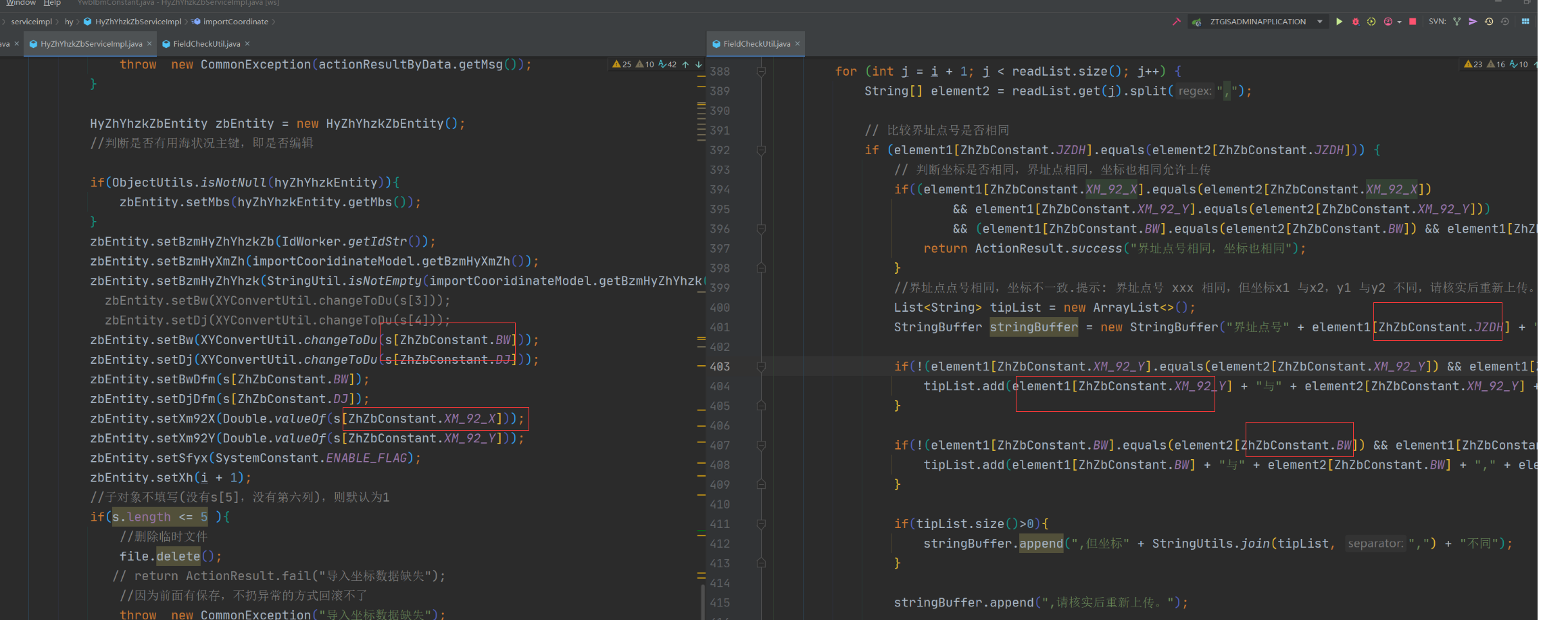
10、当一份数据需要多次使用的时候,第一次算好后转成自己格式的数据,后面有再使用,直接用转换后的数据
问题可能会如下
9.1、用户提出修改,可能要修改多个地方
9.2、可能导致手误后例如经度纬度写反
例如一下:第一个红色框已经存到zbEntity对象里面,后面应直接从zbEntity里获取
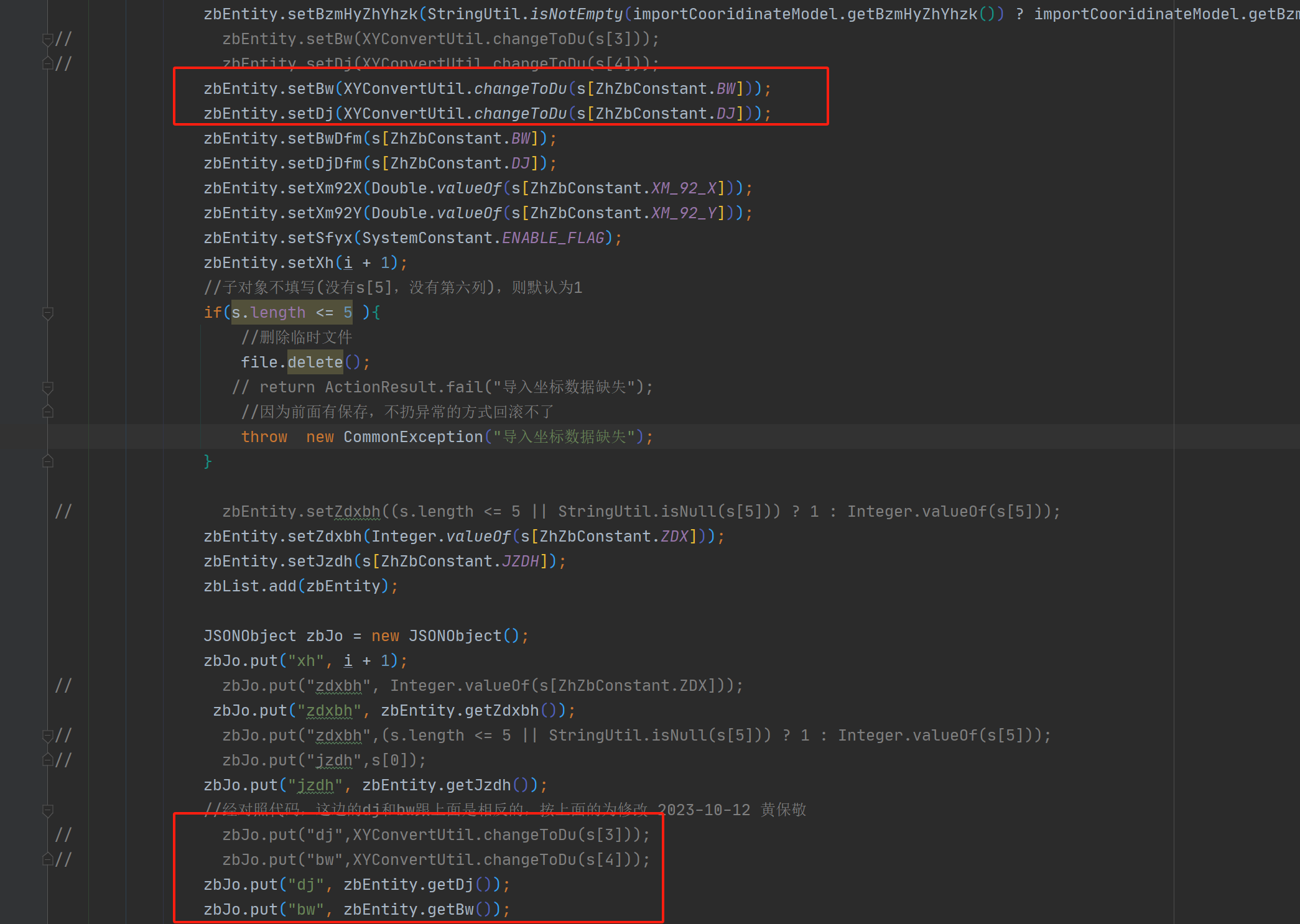
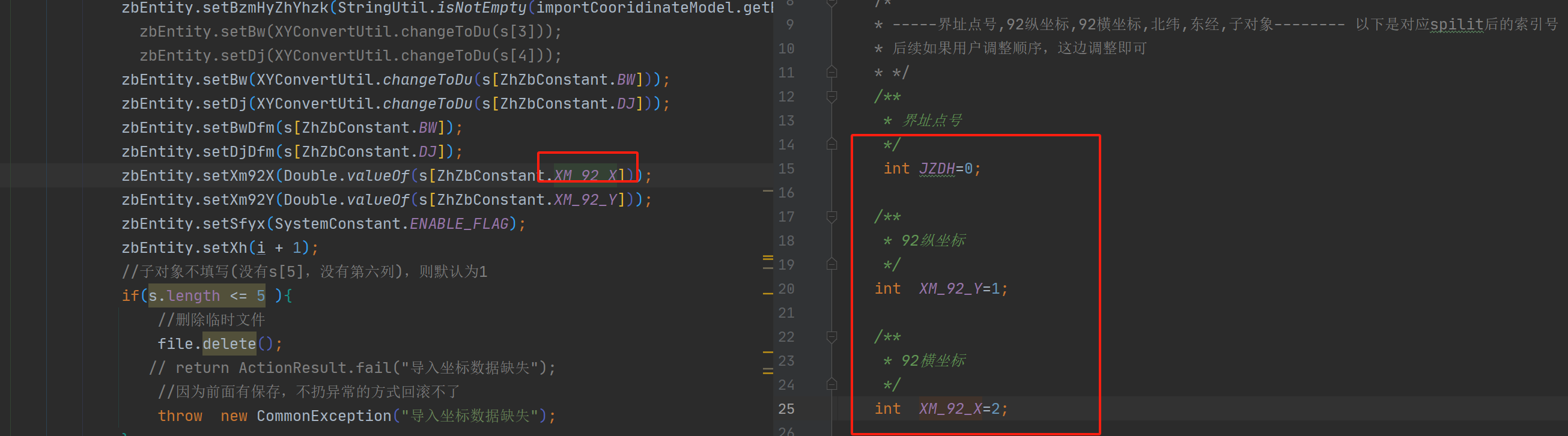
11、如果真需要String[]在多个地方使用,写索引号的时候建议写常量
好处: 11.1、根据常量名方便易读
11.2、对调字段索引号省去到处修改,常量对应的索引号修改即可
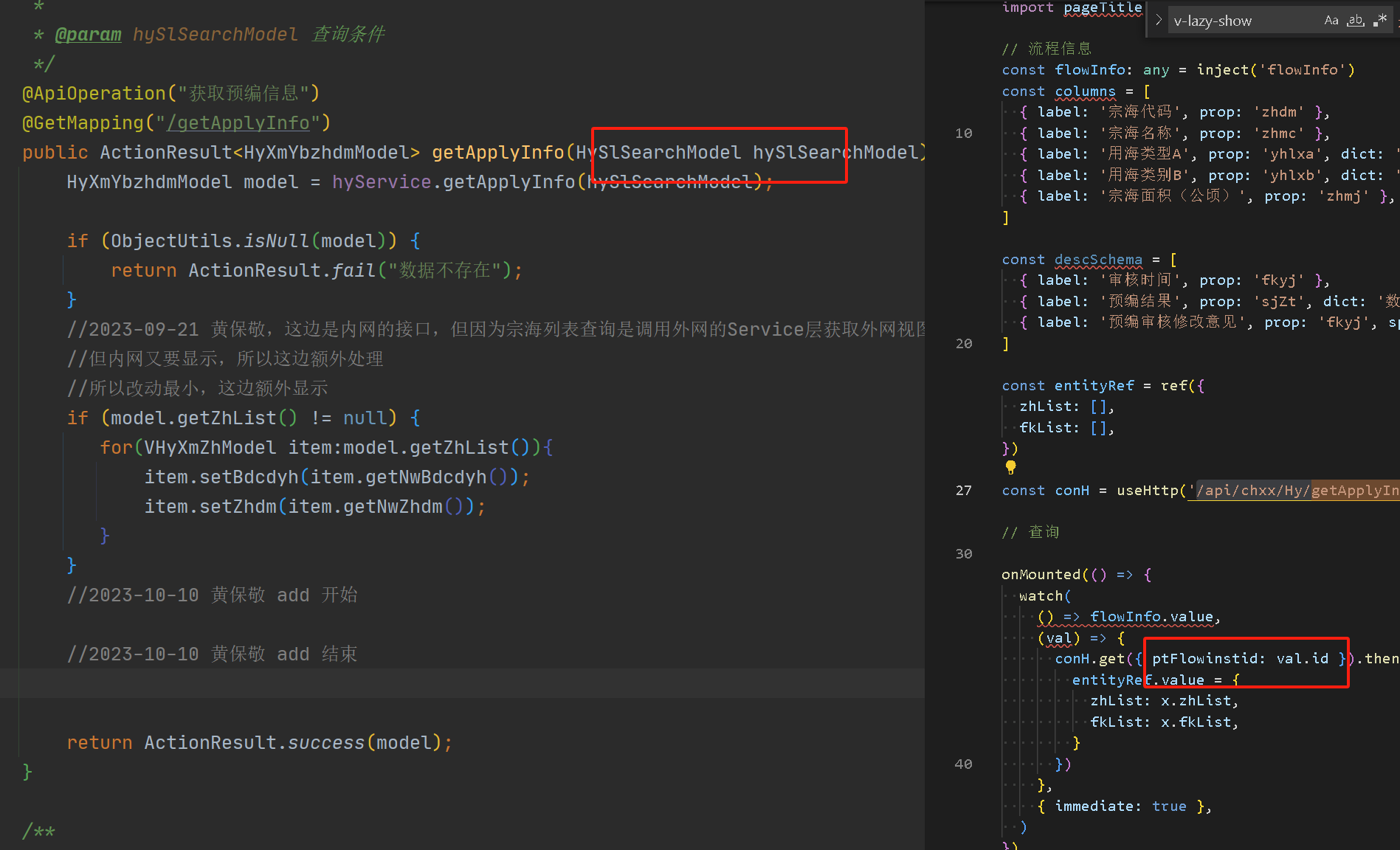
12、对应根据id或者状态业务本身查询数据等比较明确的查询,用模型类接收,导致需要去读取前端或者接口才能知道用到那些模型类参数
建议:写String xx字段等明确字段接收
模型类接收正常应用于在分页查询,保存、更新等接口是有对应的前端ui界面,能知道是对应前端页面的参数,这种情况下正常也不会在模型类写无用字段
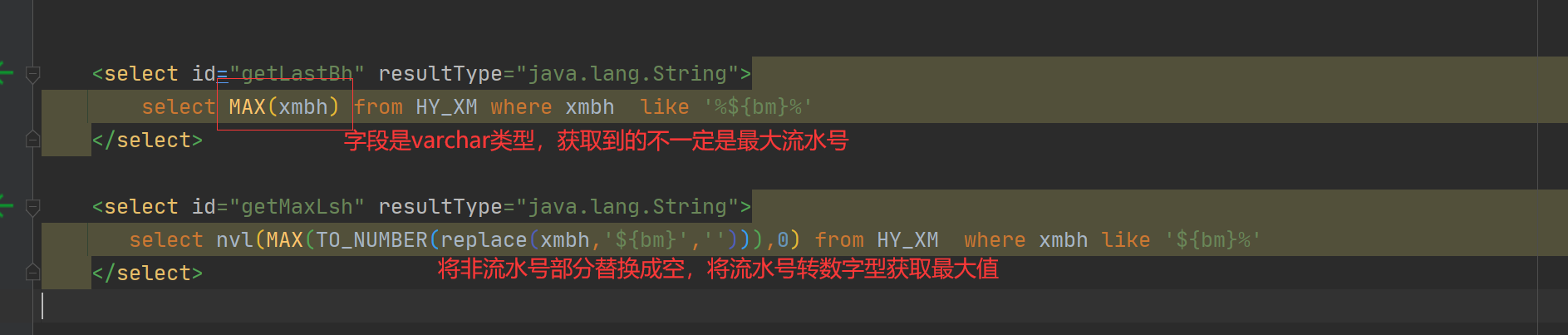
13、sql max(varchar)获取到的流水号不一定是最大那个,需转换成max(数字)确保取到最大值
场景:获取项目编号的最大流水号,可以将前缀部分替换成"",将保留下来的流水号转int(注意null不存在需转0)
14、应寻找方法避免if语句的嵌套
例如下面的例子:多次检测异常信息,检测到异常信息立马return即可,就可以避免 if嵌套
15、业务状态不要从前端缓存获取,可能其他用户已经流转走,或者本人开启多个浏览器窗口已流转走,这个时候用前端状态属于过时状态,再使用会导致业务数据存错
业务状态应以后端数据库实时的为准
- 场景1用户打开页面的时将状态获取到前端,用户点击保存、提交等操操作时前端给后端的业务状态可能已经过时
- 场景2:分页案件列表查询,有编辑按钮,但后端状态用户可能其实被他人操作不能编辑,前端编辑按钮也是过时的
16、find,get等方法只读方法里面不要写增删改数据
结论: 改方法名称,find/get只做读取数据
17、Post新增,put编辑分2个接口时,因新增和编辑会有很大一部分代码是雷同,例如校验,共同保存部分,分开写会导致可能修改2个接口
结论:公共部分抽取
18、往word模板软件替换数据时,需配置区分大小写,整个单词匹配
例如,例如数据源有bz(bz="同意")和ybzhdm,如bz先执行,ybzhdm就会变成y同意hdm ,等真正替换ybzhdm的时候就匹配不到 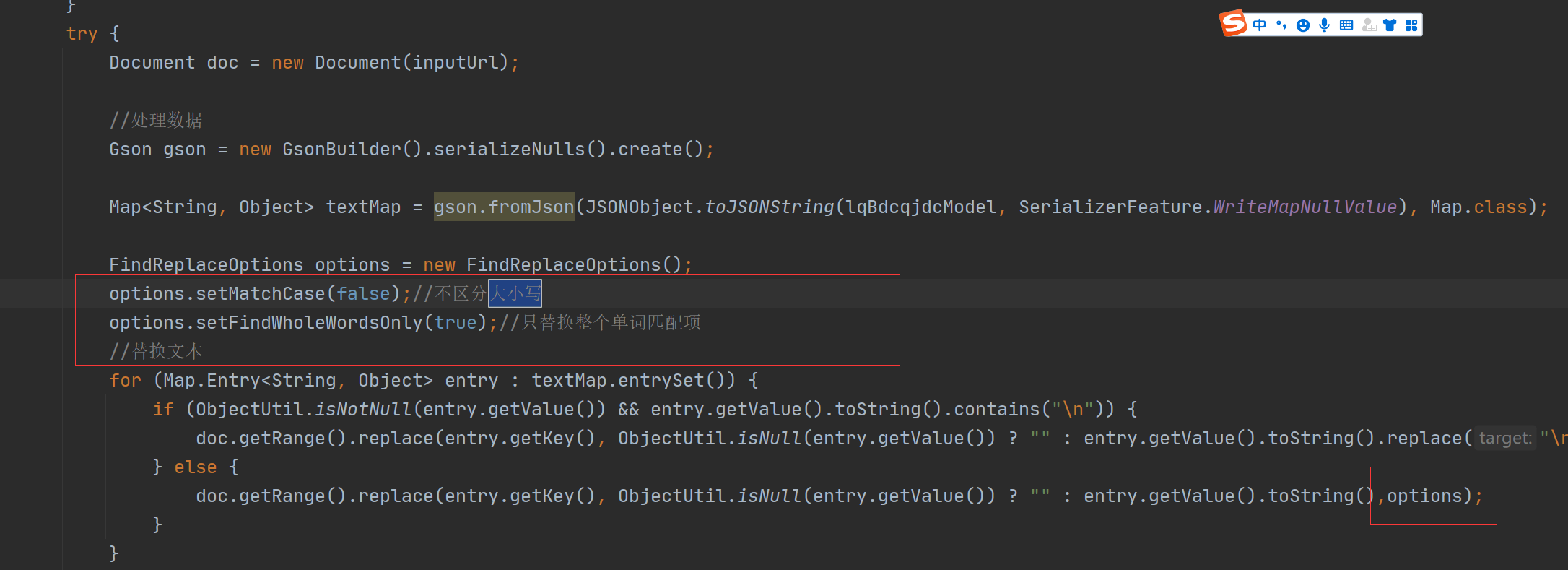
19、目前测绘信息前端是采取切片上传,后端是适配前端封装的控件
切片上传大致过程:
1、前端文件按切片上传到服务器
2、后端根据切片重新组合成完整的file对象文件
- 问题1、目前后端封装上传公共代码是跟前端monorepo匹配二次封装,若有其他端例如app,可根据自己需要用最底层的smb工具自行二次封装与自己端设计匹配
- 问题2、存在后端非切片上传文件调用切片上传相关方法(例如后端自己根据模板生成的文件就是非切片文件)
20、例如当有2个表名称一致,创建java文件的还是有2个办法
- 20.1、其中一个java文件名换个名字
- 20.2、通过注解的形式区分文件 模型类添加org.apache.ibatis.type.Alias(别名)区分开来
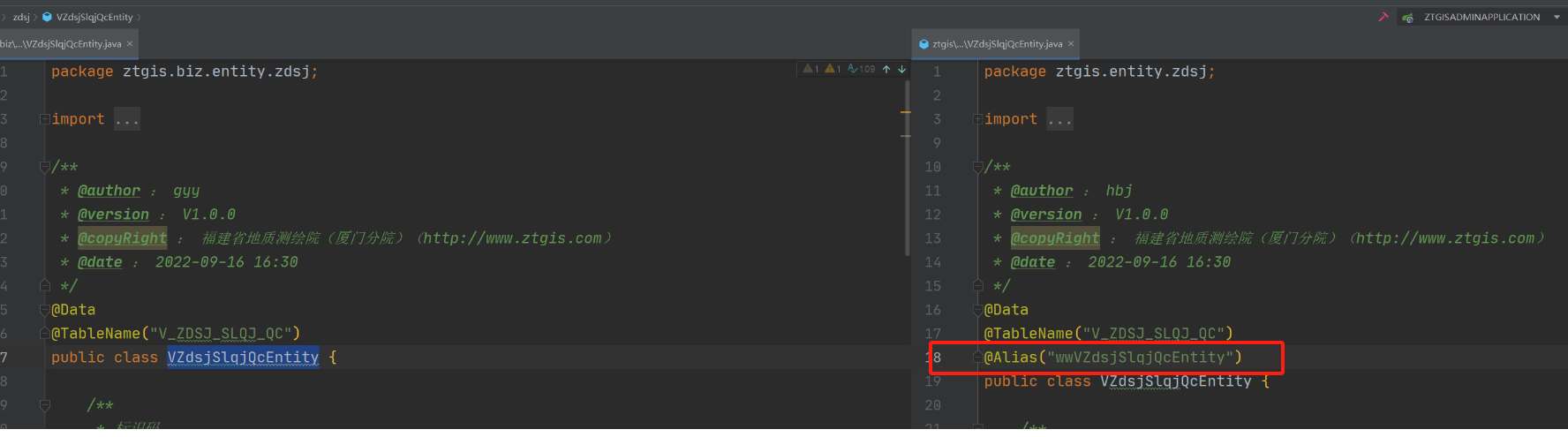 Service层,@Service("别名")例如@Service("wwVZdsjSlqjQcServicelmpl")
Service层,@Service("别名")例如@Service("wwVZdsjSlqjQcServicelmpl") 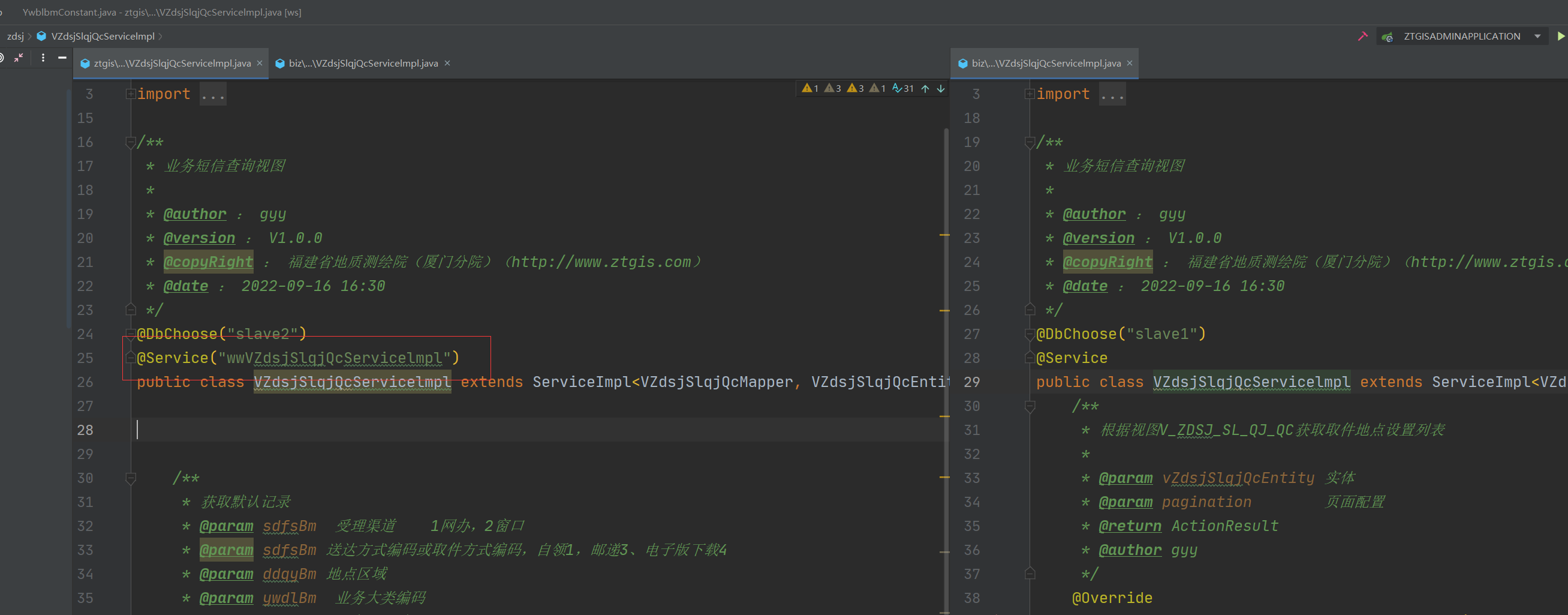
21、greatest,sum等函数需考虑null值,例如,greatest(1,null)=null,不是等于1,会导致相关业务应用的地方数据有问题
对于oracle数据库,可以用nvl将null变成0再去对比 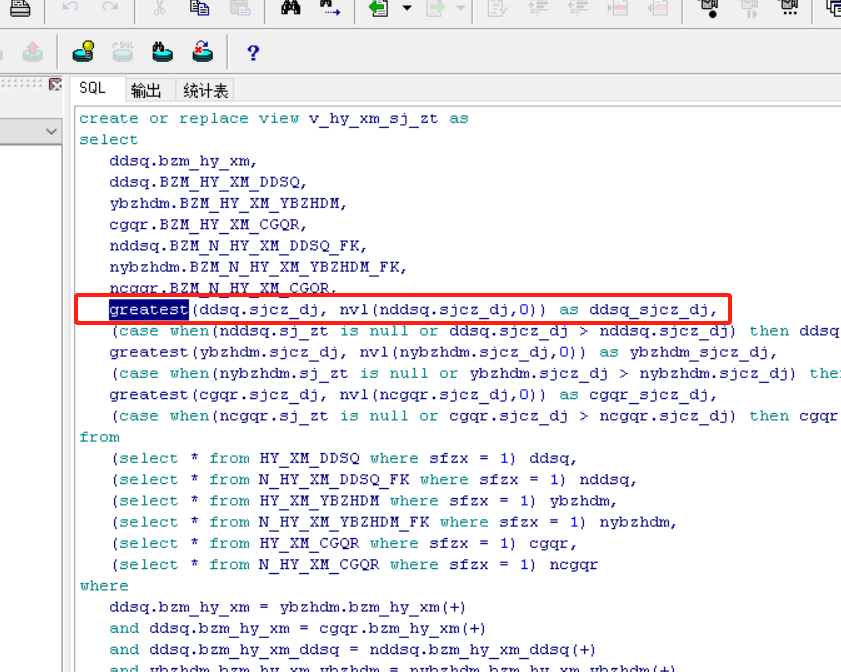

22、查询统计的时候需用count(),SQL92定义的标准统计行数的语法,经测试count()的速度也会快于其它

23、目前存在有写double,有写Decimal,有写BigDecimal(坐标,或者分析的重叠面积)
问题:例如同步数据的时候,存在Double赋值给BigDecimal,导致需要刻意转换
讨论是否做统一,比如精度要求不高用double,精度要求高用Decimal 或者统一Decimal 
结论:按实际需求,推荐统一使用Decimal,操作需求的使用double,金额BigDecimal
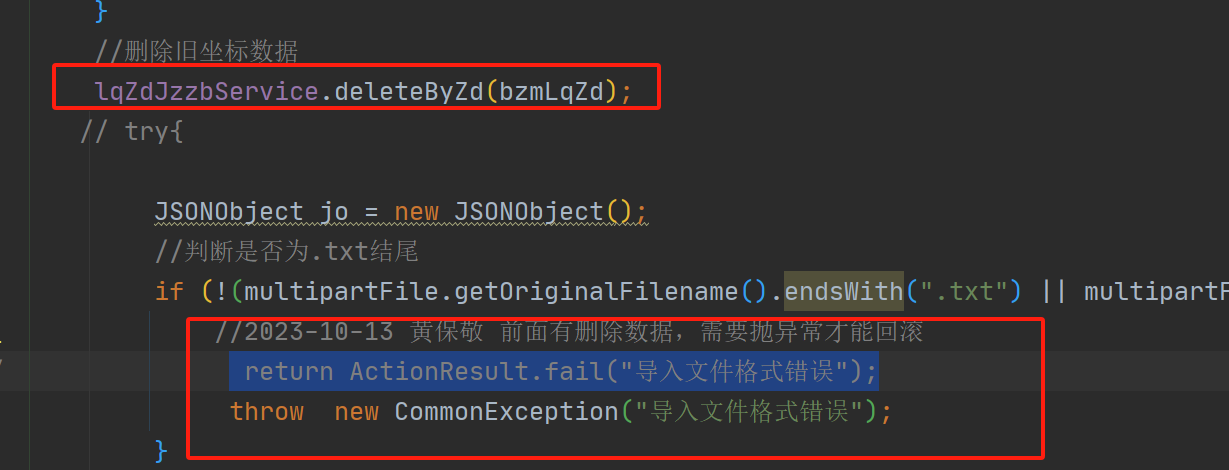
24、尽量避开增改删数据与校验不通过交错在一起,导致校验不通过都得一直抛异常的形式
例如下面的例子上传坐标,1、删除2、校验3、新增的顺序写接口,
导致2校验需要扔异常才能回滚,
校验的时若无意写错成 return ActionResult.fail("导入文件格式错误");会导致事务回滚不了
建议:先执行相关校验,校验通过后,再自行相关操作数据(例如上面的1、校验2、删除、3、新增的顺序执行) 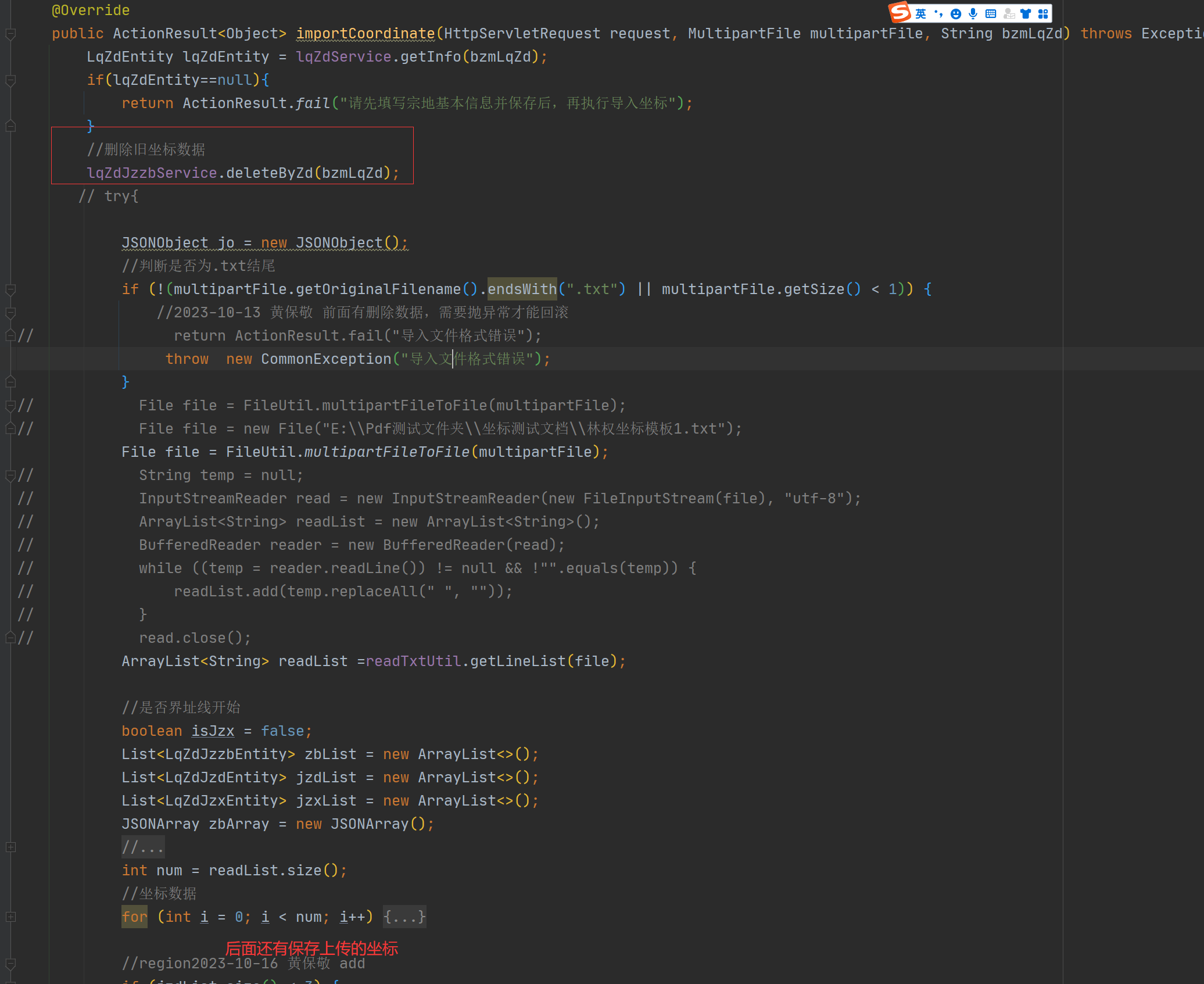
25、数据库表字段是字典的,目前存在有的写char,有的写Integer,有的写varchar
问题1:导致有的可能业务需要数据库Integer,实际java模型类映射的时写String
问题2:视图关联查询的时,两边字段类型不一致,还得转换(房屋同步公安库数据的时候,出现过有的写char,有的写varchar,关联时需要刻意转换)
结论:推荐使用varchar
26、出于特殊原因写出来的代码,需添加特殊原因注释
例如下面2个例子
- 26.1 原本外键查询应该用=,但改成like,如果不写注释,其他人来看是无法知道为什么这样做
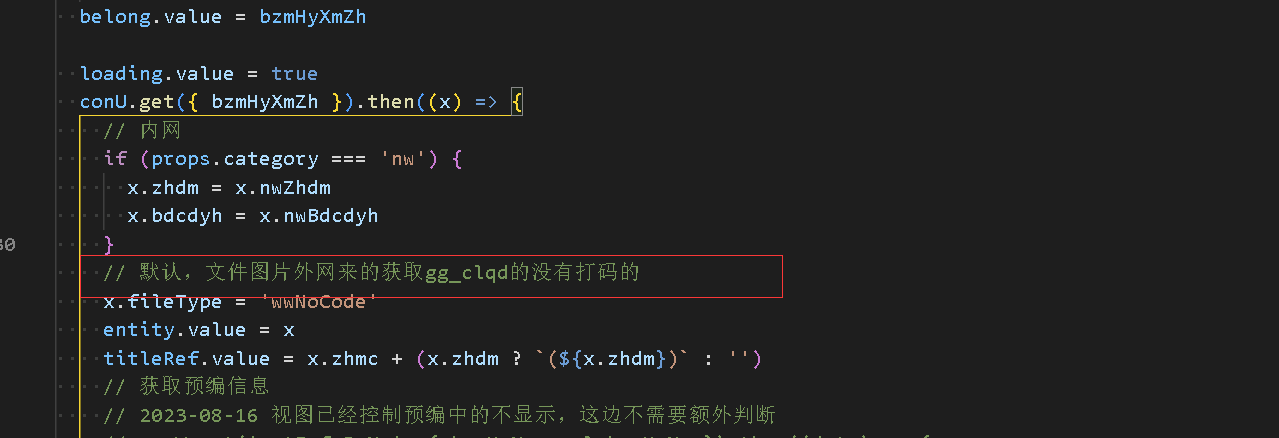
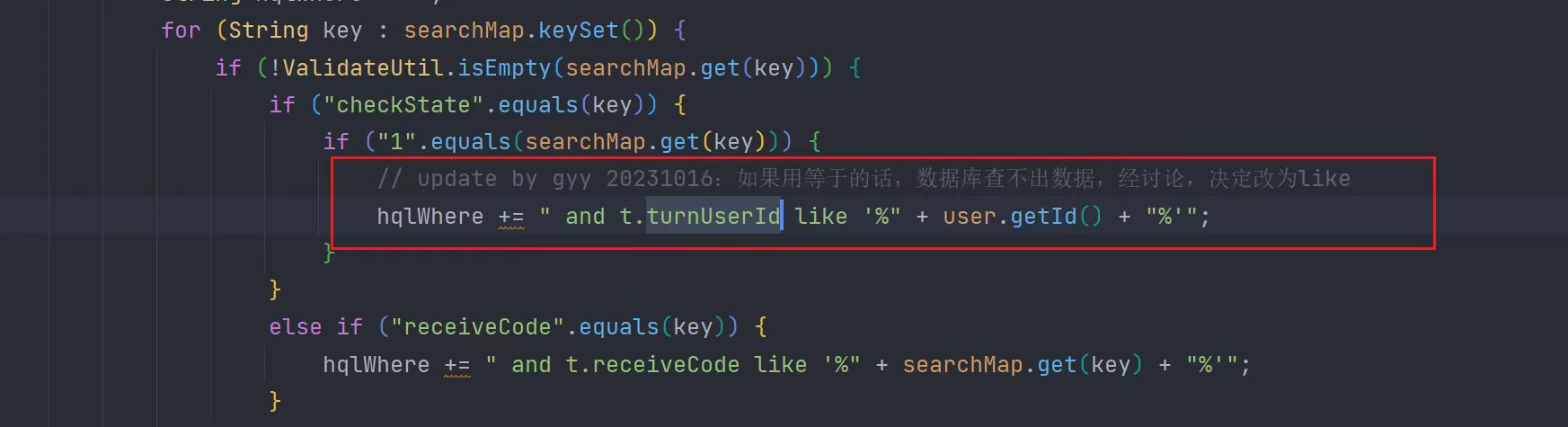
- 26.2、用户要求按照内网或外网不同入口显示不同图片,定义不同入口枚举值时需写上对应枚举值意思,方便其他人查看
以上举2个例子是出于某种特殊原因,都需要标上注释
27、如果某个需求目的是为了个获取到某个值,已有的方法也能获取到,但已有方法使用了相关不需要的代码,增加了复杂度和接手的人读取的时间,因再写一个简便的
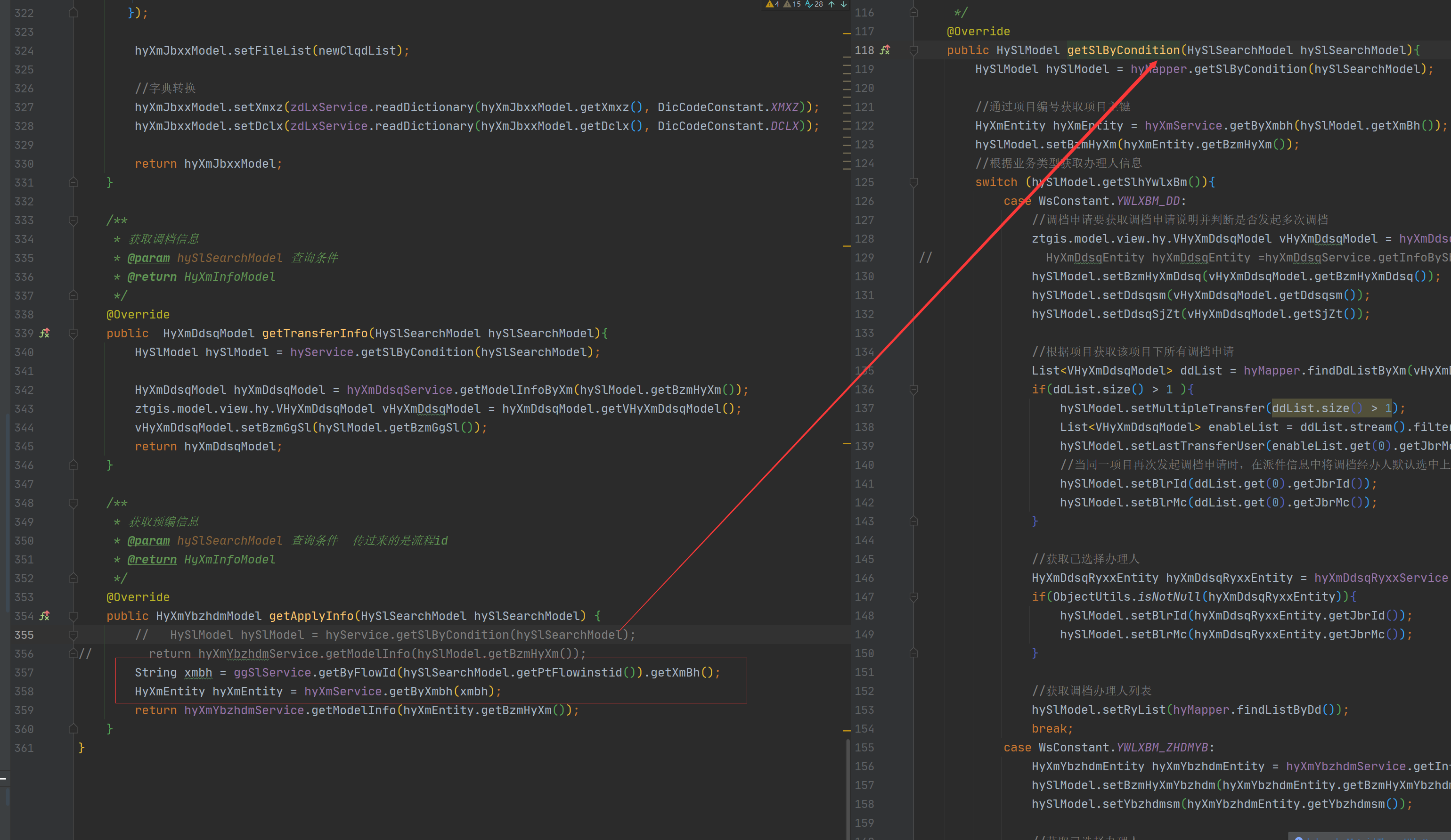
结论:抽取简单的
28、流程询问事件
- 场景:
- 第一版:保存用户填写数据和业务结束状态同一个接口
- 第二版:保存用户填写数据一个接口,业务数据状态结束在流程提交审批事件里面
- 强制:业务单据结束需写在审批事件里,不然用户提交询问点击取消就会导致业务数据提前结束(节点事件报错,流程提交会给不通过,有了类似事务的意思)
- 建议:节点事件即使不需要写业务逻辑,可以配置空实现,若上线后新需求只能在节点事件里做,会存在还在审批中的历史单据不好兼容
29、调用其他人系统,或者exe等非本系统的,给前端报错提示语因来自调用方提供的(除项目经理要求不按地方提供除外)
场景:用户反馈重叠分析失败,但提示语写的是分析失败,看不出问题,后插入内网线,远程登录内网服务器,找报错日志才知道是exe 的图层问题
应返回exe提供的报错原因去提示前端,就可以省去以上排查的相关时间花费
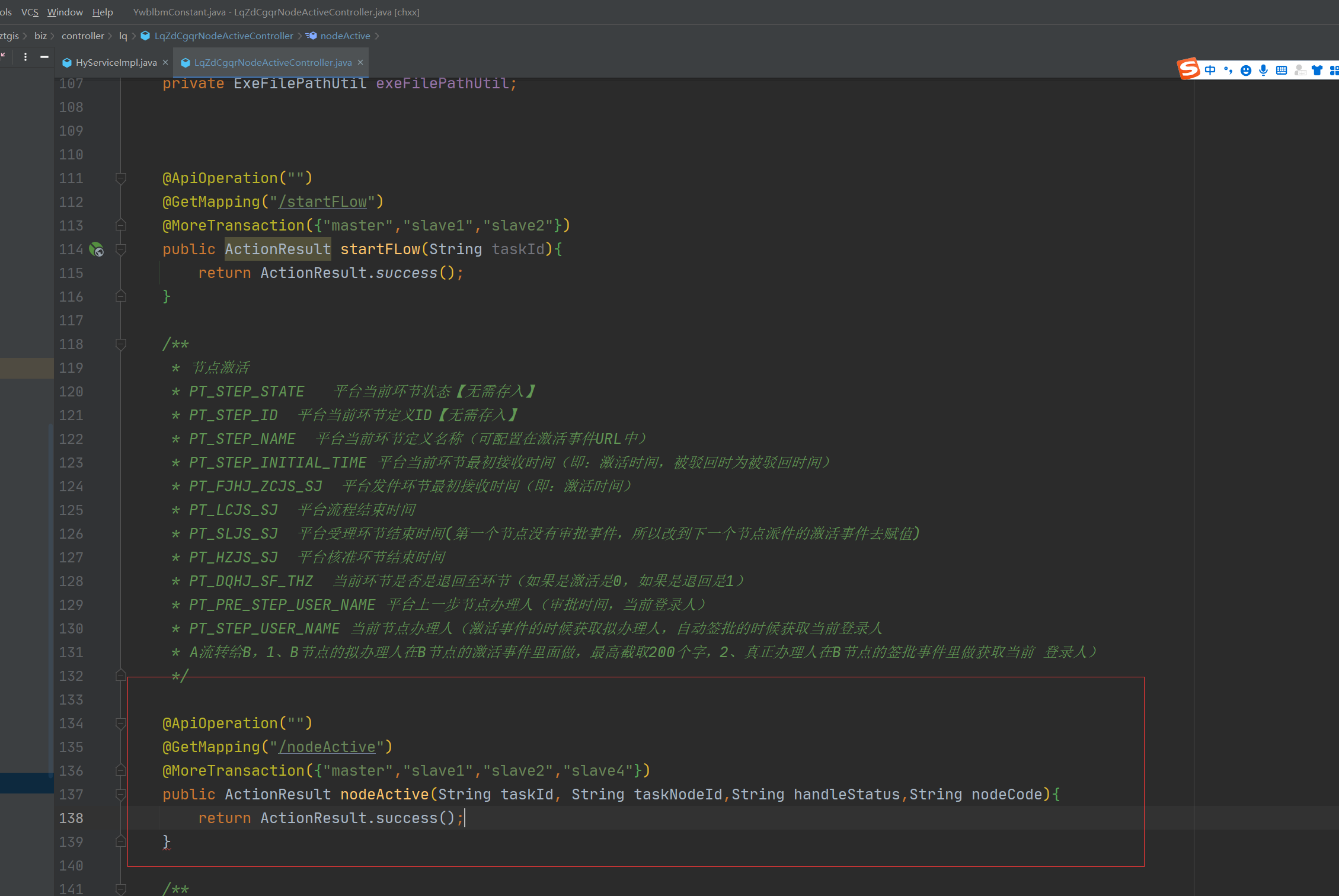
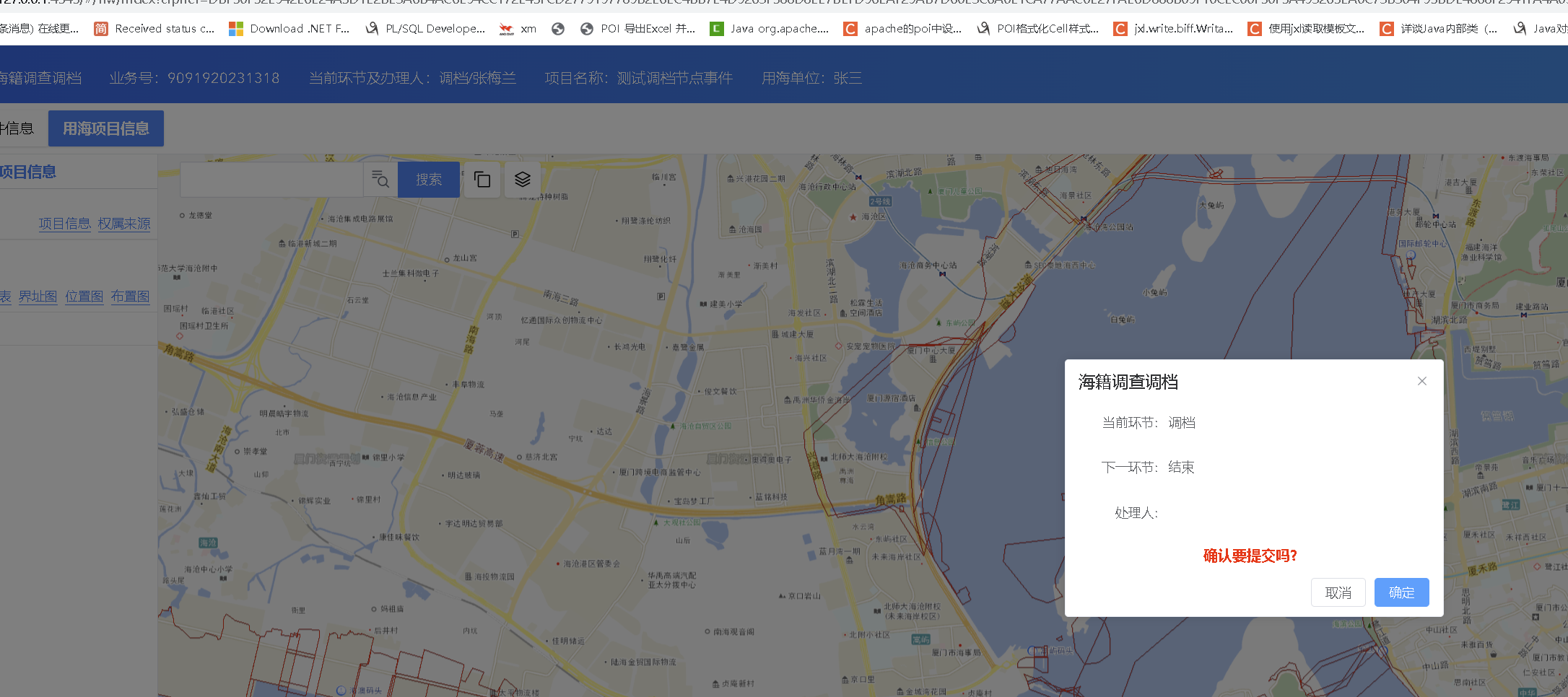
30、建议:需经过业务计算才能得出来的结论,逻辑计算应写在后端,前端只负责执行最终结果
例如下图,保存,通知修改,提交复审是否显示,应后端写业务逻辑,后端返回1或者0给前端, 前端无需关心什么时候1,什么时候0,只需要跟1或者0操作即可
(特别是小程序,android,苹果(目前我们没有)等安装在用户手机端,更新1次比较麻烦))
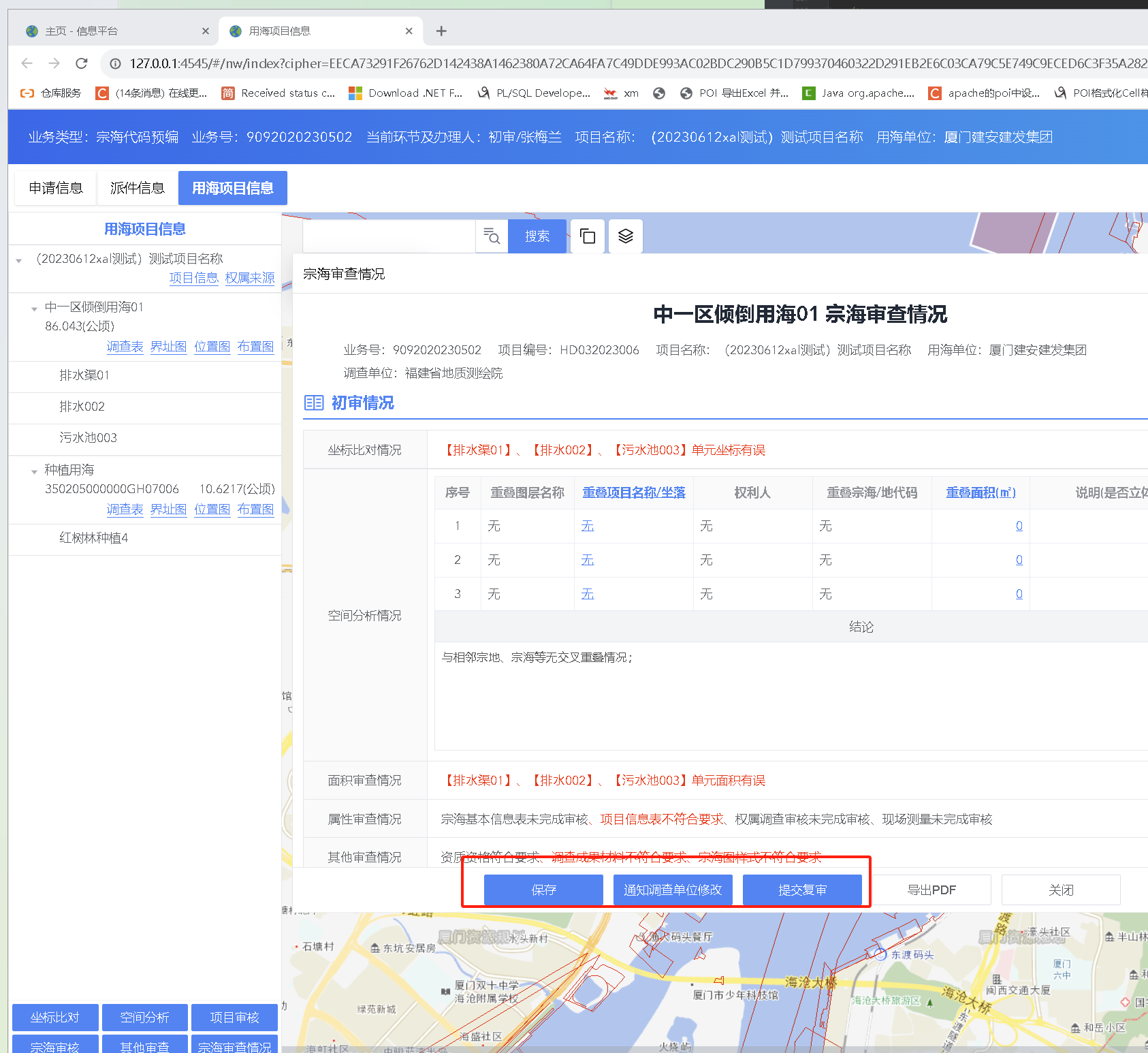
31、 throw new Exception(String.format("上传失败!原因:上传的压缩包zip包%s", fileExistMessage)); 前端是收不到这个提示语,因改为封装的公共异常throw new CommonException
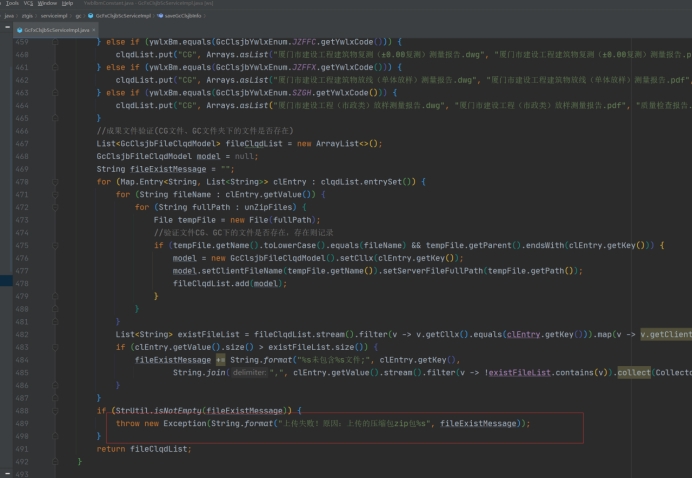
32、本身布尔值的,不建议写==false或者==true
true本身已经是true,不需要==true二次强调是true
例如下面这个判断空正常是 StrUtil.isEmpty(bzmN)
即使是要按取反写,建议不要写==false(这个理论上可以,实际没这么写),!字符含有取反的意思 !StrUtil.isNotEmpty(bzmN)表示不为空取反,==false还得反应一下
33、有常量应常量写在前,确保百分百不会报空指针(即使现有的入参在被调用的地方判断了空指针,但方法可能被多次复用,建议在常量存在的时,优先使用常量)

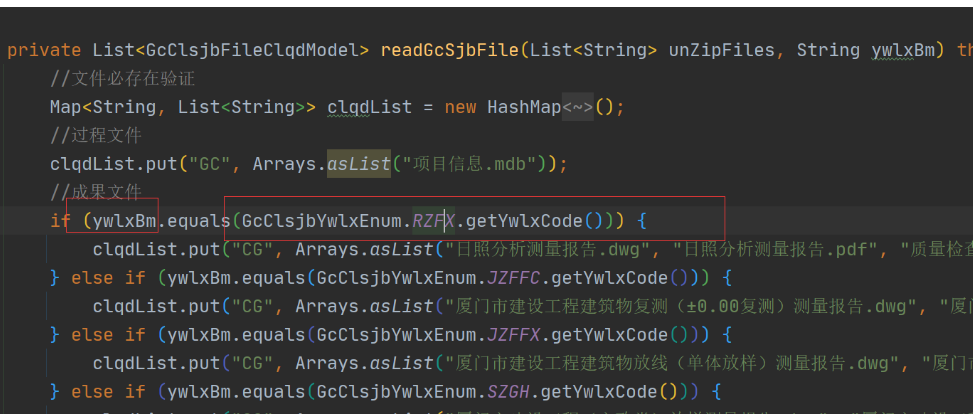
34、不允许用ui上显示的名称去做查询数据,应添加名称对应编码字段
ui上显示的用户可能会要求修改,应按照会修改去设计代码(即名称不能作为查询条件使用,应使用名称对应的编码)
原则就是名称不参与业务查询使用,不能应修改需要调整代码
例如:其他材料,相关业务引用“其他材料”文件记录查询条件是根据名称字段写死"其他材料",导致相关代码需要修改


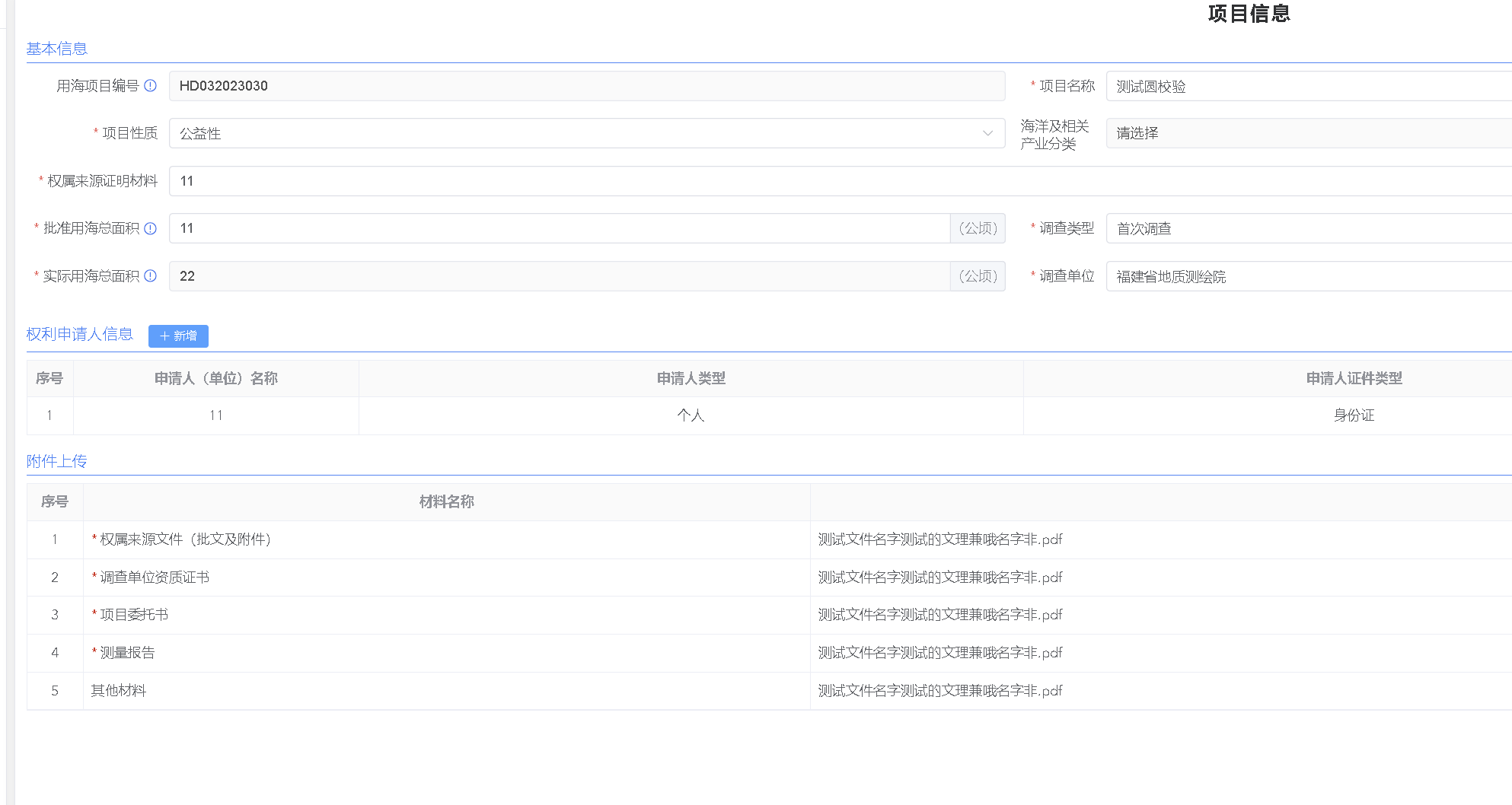
35、application.yml若添加业务特有配置参数,不允许在公共ConfigValueUtil里添加,需在自己业务特有模块添加
自己业务模块新建类,添加自己特有字段是支持(svn若支持锁定特定文件ConfigValueUtil,建议业务人员不允许提交)
36、生产环境禁止日志打印方式System.out 或System.err 或e.printStackTrace()
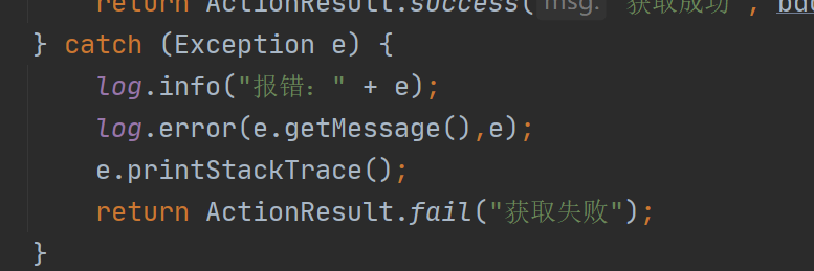
原因如下

结论:使用log.debug(),生产环境禁用debug日志