Appearance
AI
人工智能(Artificial Intelligence)
什么是AI
它是一门研究如何使计算机能够像人一样思考和行动的科学与技术。简单来说,AI指的是赋予计算机以智能的能力,使其能够感知、理解、学习、推理和决策,以完成各种任务
是一个 黑盒函数。对输入的内容,通过参数映射,最终反馈到一个最有可能(概率最高)的输出结果。目前的AI并不真正“理解”人类的含义,而是通过数据驱动的模式匹配和概率计算来模拟“理解”的过程
发展历程
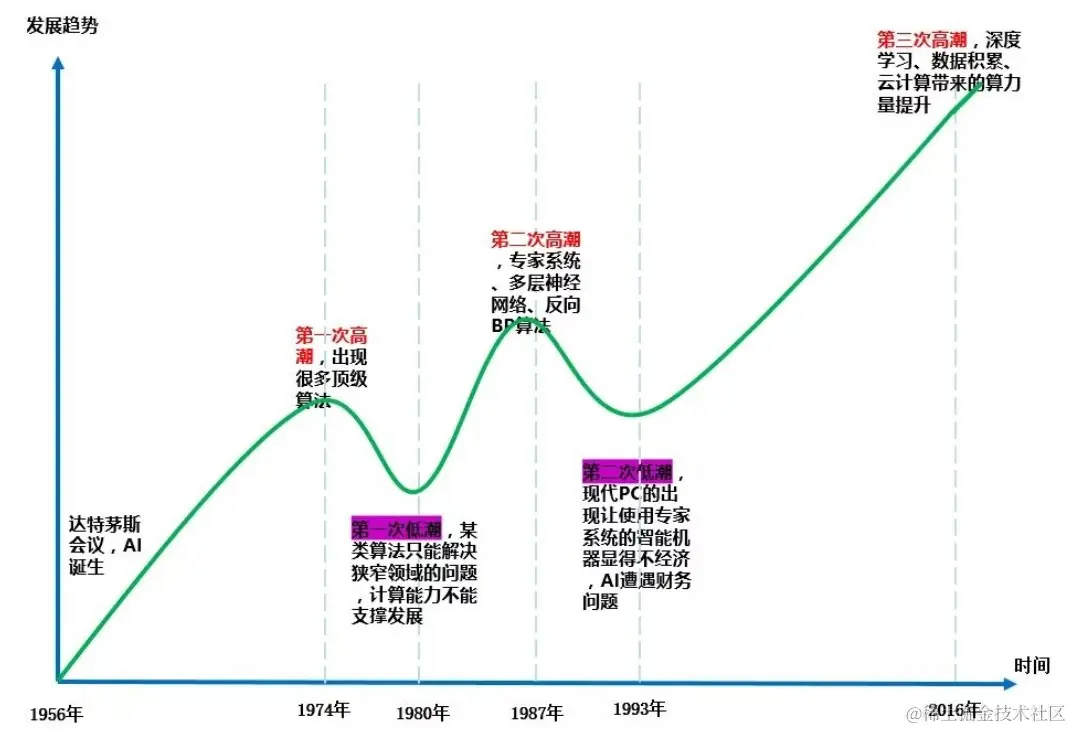
早期探索(1950-1970年代):人工智能的概念最早由图灵提出,他提出了“图灵测试”,即判断一台机器是否具有智能。随后,人工智能领域涌现了许多重要里程碑,例如达特茅斯会议(1956年)标志着人工智能成为独立的研究领域;约翰·麦卡锡等人提出了人工智能的基本概念和方法;在这个时期,人工智能的研究集中在推理、搜索、知识表示等领域。
知识工程时代(1980-1990年代):这一时期,研究人员开始将专家知识系统化,发展了专家系统等符号主义方法,并取得了一定的成功。但是,由于专家系统的实际应用效果不如预期,人工智能研究进入了低谷期。
统计学习时代(1990-2010年代):随着计算机技术和数据处理能力的提升,统计学习方法开始受到关注。机器学习、神经网络等技术逐渐崛起,支持向量机(SVM)、决策树、随机森林等方法被广泛应用。同时,大量的实际数据催生了大数据时代,为机器学习提供了丰富的训练材料。
深度学习时代(2010年至今):深度学习作为机器学习的一个分支,以其优异的性能在图像识别、语音识别等领域大放异彩。神经网络模型的深度和规模不断增加,包括卷积神经网络(CNN)、循环神经网络(RNN)和变压器模型等,大大提高了人工智能在各个领域的应用效果。2017年谷歌发布基于“自注意力机制”的深度学习模型“Transformer架构”,成为现代大模型的基础,使得模型具有强上下文能力,矩阵计算,可以并行计算GPU加速
为什么 "智能"
基础原理
基于数据驱动和算法模型。通过对大量数据进行学习和训练,从中学习规律,并不断提高其性能和准确度。
具体来说,对输入的数据进行 处理和分析操作,以提取出数据中的关键特征。然后,利用这些特征进行模型训练和推理,通过调整模型的参数和权重来最大程度地减小预测误差,从而使AI系统能够根据输入数据预测输出结果。
理解文本过程
文本的token化处理
** 将文本拆解为单词基础单元(单词与token并不是一一对应;可以是一个单词一个token,一个单词多个token,或者多个单词一个token; 不同分词器分词的方式不同,token数量也不同)**
sh
原始文本: "深度学习很有趣!"
↓
按词分词: ["深度", "学习", "很", "有趣", "!"]
↓
按子词分词(BPE): ["深", "度", "学", "习", "很", "有", "趣", "!"]不同模型采用的分词策略不尽相同
转化为词嵌入
通过嵌入矩阵(一个模型只有一套固定的嵌入矩阵把token转成向量矩阵),将Token映射到一个固定维度的连续向量;(相似概念点会映射在向量的相近位置;国王 - 男 + 女 ≈ 女王)
sh
# 词表大小=4,嵌入维度n,纬度越高表示的内容越多
embedding_matrix = [
[0.1, 0.2, ..., 0.3], # "I" 的向量
[0.4, 0.5, ..., 0.6], # "love" 的向量
[0.7, 0.8, ..., 0.9], # "NLP" 的向量
[0.0, 0.0, ..., 0.0] # "<UNK>" 的向量
]
# 输入的token
["I", "love", "NLP"]
# 转换为
[[0.1, ...], [0.4, ...], [0.7, ...]]| 类型 | 示例模型 | 特点 |
|---|---|---|
| 静态词嵌入 | Word2Vec, GloVe | 每个 Token 的向量固定,不依赖上下文(如 "bank" 在 "河岸" 和 "银行" 中向量相同)。 |
| 动态词嵌入 | BERT, GPT | 根据上下文动态生成向量(如 "bank" 在不同句子中向量不同)。 |
那这里就有个问题:那市场上的大模型采用同一个嵌入矩阵,那他们的词嵌入不就一致了?
少部分研究型模型会在预训练的嵌入矩阵为基础,做微调;其它大型预训练模型(如BERT、GPT系列)都是从头开始训练嵌入层的,因为它们需要让嵌入层适应整个模型的训练目标和上下文信息
计算依赖关系
使用自注意力机制,计算token之间的依赖关系(使用位置编码【token出现的位置】、词嵌入计算,算出各个文本中每个元素【token】与其他元素的相关性),动态地为每个元素分配注意力权重(不同元素之间的关系大小),使得文章对话具有上下文。
自注意力权重计算:

怎么训练
数据准备 → 2. 模型设计 → 3. 模型训练 → 4. 评估验证 → 5. 调优优化 → 6. 部署监控
数据准备:构建高质量数据集
- 数据收集:公开数据集(ImageNet、COCO)、爬虫抓取、人工标注、传感器生成等
- 数据清洗:去重(删除重复样本)、处理缺失值(填充或删除缺失字段)、纠正错误(如错误标签、噪声数据)
- 数据预处理:统一数据格式、分词
- 数据划分:训练集(70%):用于模型参数更新、验证集(15%):用于超参数调优和早停、测试集(15%):最终评估模型性能
模型设计:选择与搭建架构
根据数据特点选择合适的模型架构
评估验证:量化模型性能
- 损失函数:分类任务(交叉熵损失)、回归任务(均方误差)
- 优化器:SGD(基础优化器,带动量(Momentum)可加速收敛)、Adam(自适应学习率)
- 循环训练
- 前向传播:输入数据计算预测值。
- 反向传播:计算梯度并更新参数。
- 关键技巧:学习率调度(动态调整学习率()、早停(验证集损失不再下降时终止训练)
调优优化:提升模型表现
部署与监控:落地应用
不同需求选择不同的模型架构
模型训练:优化参数以拟合数据
不同训练对比
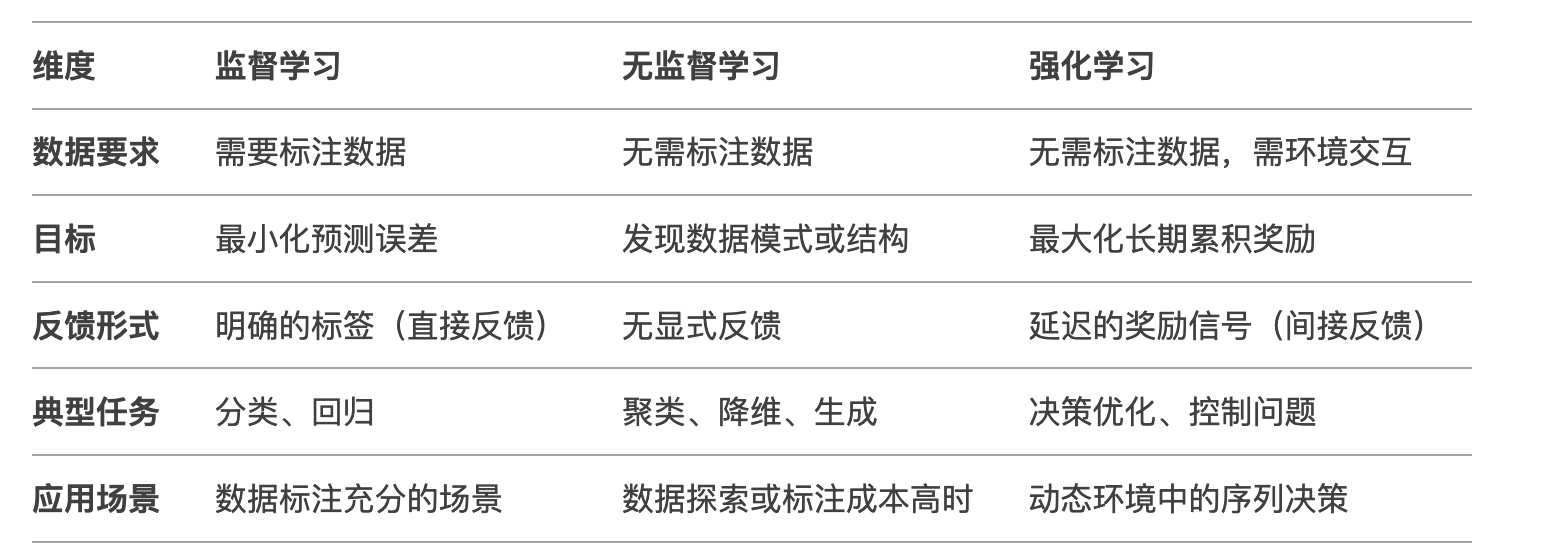
- 无监督学习
数据没有标签,发现数据的内在结构,做数据的分组和聚类。通过从数据中自动发现模式、结构和规律,为模型提供有价值的信息。可用于数据基座的处理
- 监督学习
训练过程:对参数、词嵌入矩阵、QKV矩阵等的持续调整优化
通过使用带有标签的数据集进行训练,使模型能够从输入数据预测正确的输出
- 强化学习
动态交互,奖惩机制
常见问题
- 数据问题:噪声过多、样本不均衡(如 99% 的负样本)。数据差
- 模型欠拟合:结构过于简单(如单层线性模型拟合非线性数据)。 训练不够
- 过拟合:模型复杂度过高,记忆训练数据但泛化差。 训练过度
- 超参数不当:学习率过高(震荡不收敛)或过低(训练过慢)参数配置不对
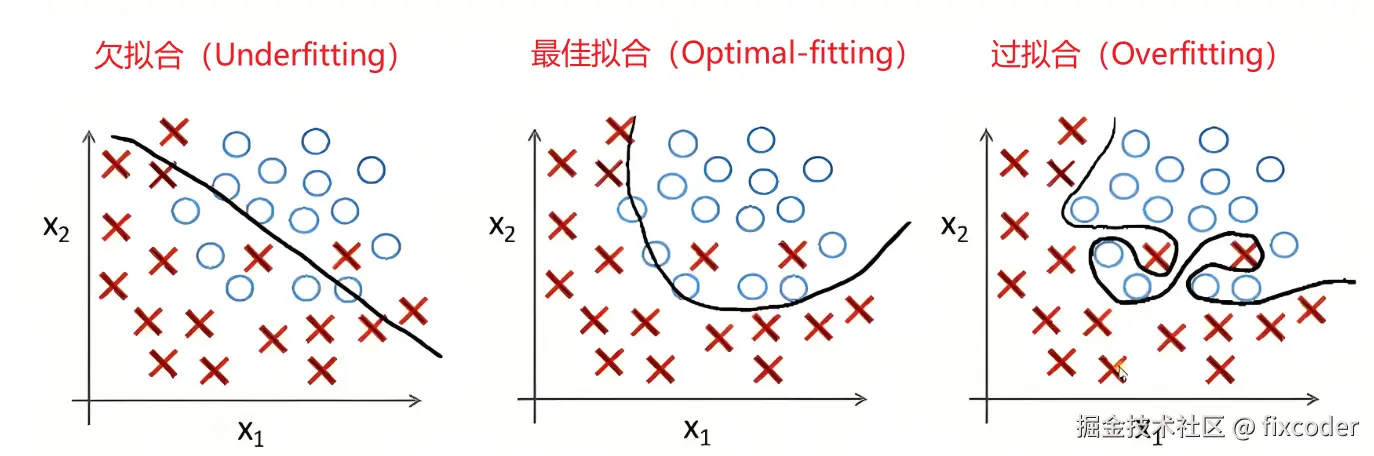
所以,超参数是什么?
用于控制学习过程和算法行为的参数。与模型参数不同,超参数不是通过训练数据直接学习得到的,而是由实践者根据经验和实验预先设定的数据,就是要学习到什么程度,
sh
学习率(Learning Rate):决定了参数更新的速度,在梯度下降算法中非常关键。如果学习率设置得太高,可能导致模型无法收敛;如果太低,则可能使训练过程非常缓慢,甚至陷入局部最优解。
批量大小(Batch Size):每次迭代时用于梯度估计的数据样本数量。批量大小的选择会影响模型的稳定性和收敛速度。
神经网络中的层数和每层的神经元数:这些架构层面的选择直接影响模型的能力,过小的网络可能无法捕捉复杂模式,而过大的网络则可能导致过拟合。
正则化系数(Regularization Coefficient):用于控制模型复杂度,防止过拟合。正则化强度过高会使得模型欠拟合,反之则可能导致过拟合。训练过程

结论
虽然AI在某些方面表现出了一定的理解和思考能力,但其仍然是由算法和模型驱动的,并不具备真正的主观意识和自主思考能力。AI的理解和思考是基于已有的数据和知识进行的,其处理方式和结果受到算法和模型的限制。因此,在使用AI时,需要充分考虑其局限性和适用性,并结合人类的专业知识和判断来进行决策和处理。
使用现状
| 模型 | 使用人数 | 使用场景 | 备注 |
|---|---|---|---|
| DeepSeek | - | 聊天;写文档; | |
| 通义千问/灵码 | - | 会议记录;做PPT;代码辅助 | |
| 文心一言 | 3 | 聊天问答;代码辅助 | |
| GPT | 2 | 聊天问答;代码辅助 | |
| kimi | 2 | 用于对话;生成图片;ppt生成 | |
| AI ppt | 1 | ppt快速生成 | |
| MarsCode AI | 1 | 前端代码自动生成 | |
| 星绘 | 1 | 图片生成、视频生成 | |
| 豆包 | 2 | 日常问答 | |
| 即梦AI | 1 | 生成图片;视频生成 | |
| claude | 1 | 前端代码生成 | |
| copilot | 1 | 个人知识库 | |
| mastergo | 1 | 页面设计 | |
| V0 | 1 | 页面设计 | |
| Cherry Studio | 1 | 本地知识库 |
AI / AGI
主流领域
自然语言处理(NLP)
- 技术方向:文本生成(GPT-4、Claude)、机器翻译(Google Translate)、情感分析、问答系统、语音识别(ASR)与合成(TTS)。
- 应用场景:智能客服(如阿里小蜜)、法律文书自动生成、会议纪要整理、多语言实时翻译(DeepL)。
计算机视觉
- 技术方向:图像分类(ResNet)、目标检测(YOLO)、图像分割(Mask R-CNN)、人脸识别、视频分析。
- 应用场景:安防监控(海康威视)、医学影像诊断(AI辅助阅片)、工业质检(瑕疵检测)、自动驾驶感知。
自动驾驶与智能交通
- 技术方向:环境感知(激光雷达、多传感器融合)、路径规划、决策控制、高精地图。
- 应用场景:L4级自动驾驶(Waymo、Tesla FSD)、无人机物流(Amazon Prime Air)、交通流量优化。
医疗健康
- 技术方向:疾病预测(AI+基因组学)、医学影像分析、药物分子设计(AlphaFold)、个性化治疗。
- 应用场景:癌症早期筛查(腾讯觅影)、手术机器人(达芬奇系统)、电子病历智能管理。
机器人技术
- 技术方向:运动控制(波士顿动力 Atlas)、人机协作(协作机器人)、服务机器人(送餐、导览)。
- 应用场景:家庭服务(扫地机器人 Roomba)、医疗护理机器人、太空探索(NASA火星车)。
推荐与广告系统
- 技术方向:协同过滤(用户行为分析)、深度学习推荐模型(YouTube DNN)、点击率预测(CTR)。
- 应用场景:电商个性化推荐(淘宝“猜你喜欢”)、短视频内容分发(TikTok算法)、精准广告投放。
游戏与虚拟世界
- 技术方向:游戏AI(AlphaStar、OpenAI Five)、NPC行为模拟、程序化内容生成(PCG)。
- 应用场景:电竞对手训练、元宇宙虚拟角色(Meta Avatars)、AI生成游戏关卡。
智能制造与工业4.0
金融科技(FinTech)
教育与科研
环境与可持续发展
伦理、安全与治理
。。。。。
通用型AI(AGI)
Manus 。。。。。